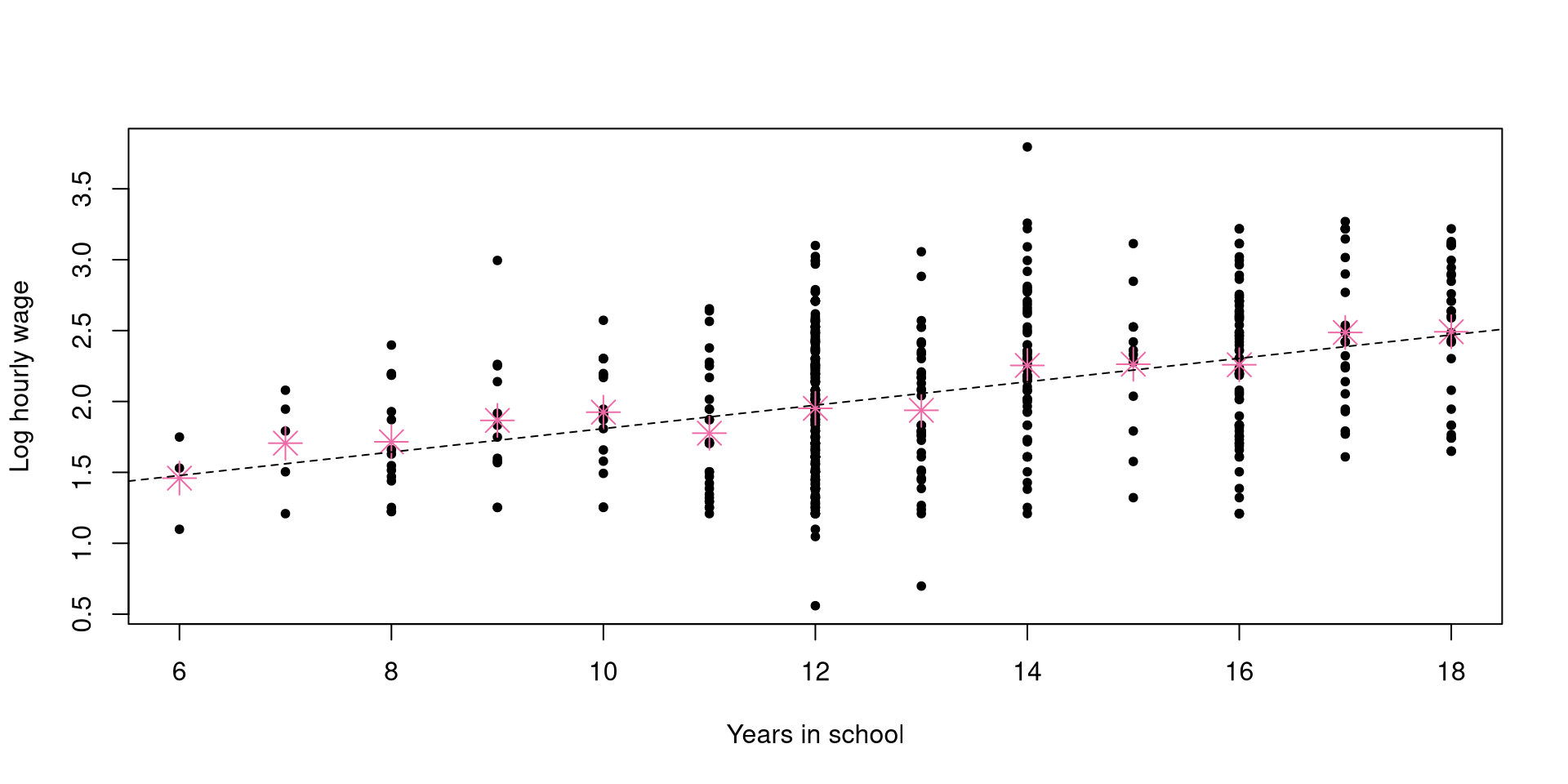
[1] 0 [1] 0 1 1 0 0 0 0 0 1 0 [1] 1 2 3 4 5 6 7 8 9 10 [1] 1 3 6 10 15 21 28 36 45 55(before seeing the data)
Andrew Pua
We calculated summaries and linear regressions using whatever data we have on hand.
These descriptions could be insightful for what they are but what exactly do we learn from these descriptions?
We have to think hard about these summaries and linear regressions before doing any computations.
I have drawn some of the technical materials from Whittle (2000), a very unconventional book on probability.
Other materials were drawn from Aronow and Miller (2019), Angrist and Pischke (2009, 2014).
Other references mentioned in the housekeeping slides were also used but are less recognizable.
What you have seen before are empirical quantities.
These empirical quantities are subject to variation.
To truly understand what these empirical quantities are actually all about, we cannot avoid abstraction.
What I mean by abstraction is that we are engaging in a thought experiment where we think of empirical quantities as having some “order” which could be studied mathematically.
We can create theoretical (idealized) counterparts of these empirical quantities by:
The starting point is that what we observe in the data have arisen from a random process or what others call a data generating process.
This is a philosophical advance and a different way of thinking.
Random is not the same as haphazard.
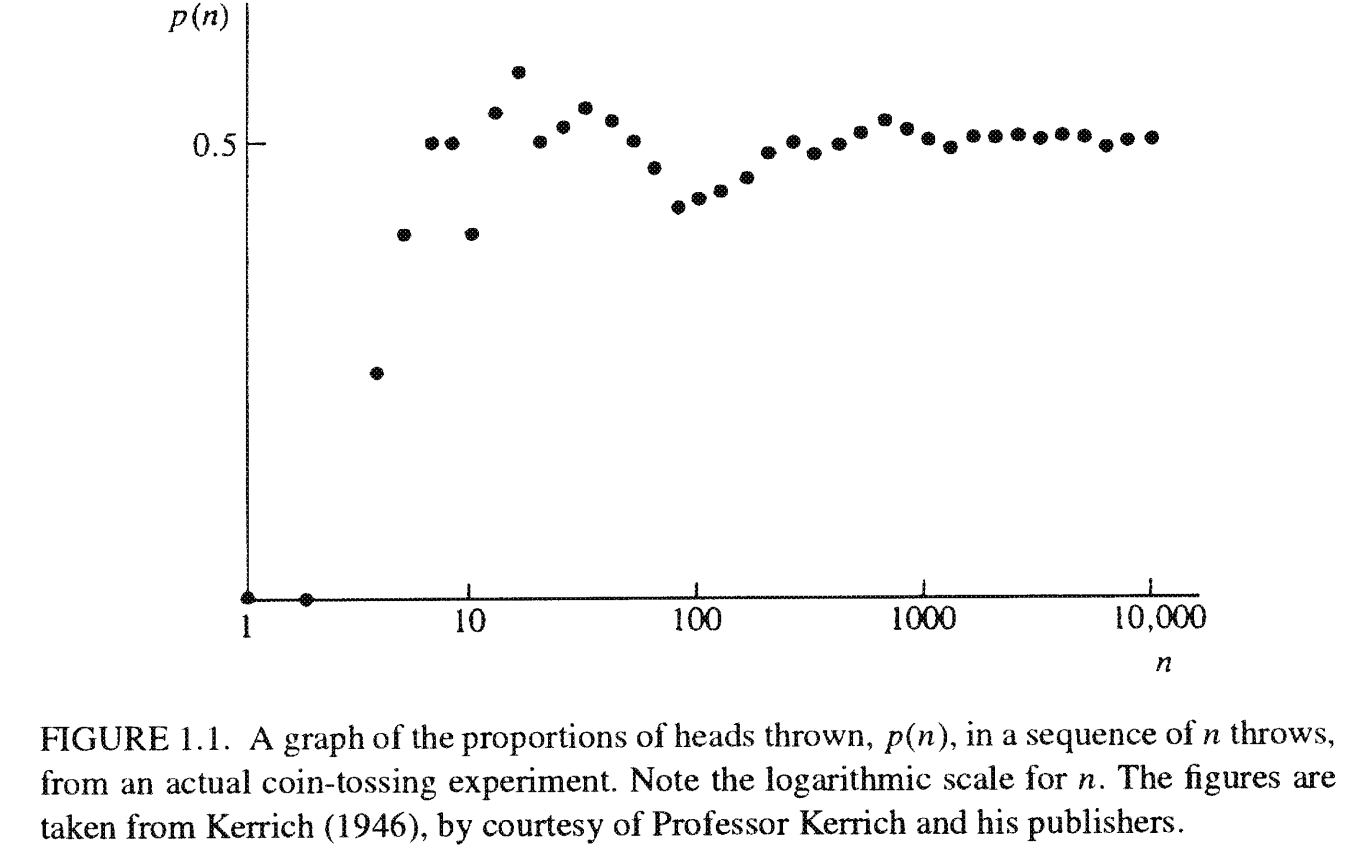
Think of the experiment where you toss a coin.
There are two possible outcomes or realizations (heads or tails).
Which outcome shows up is not known in advance.
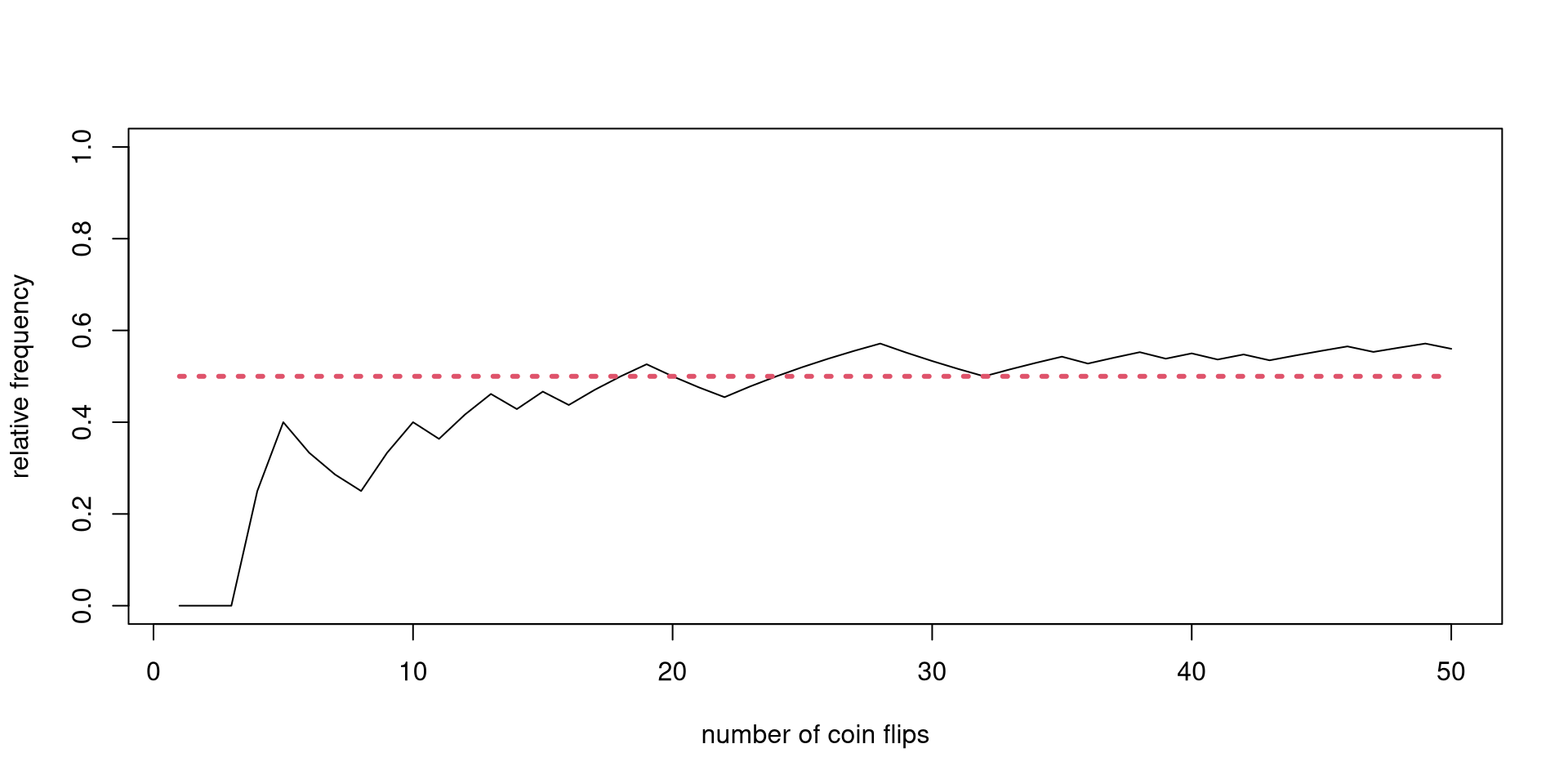
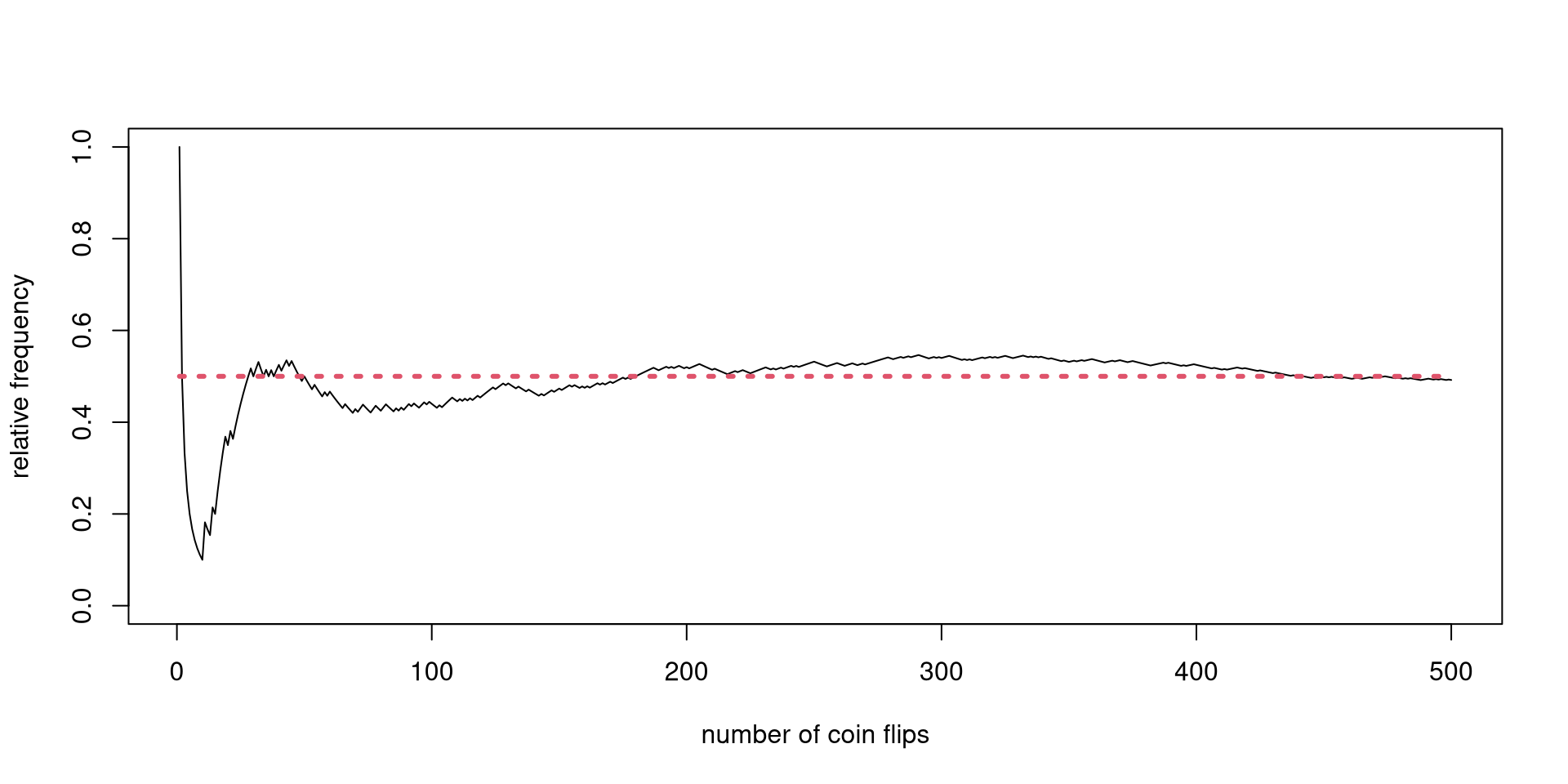
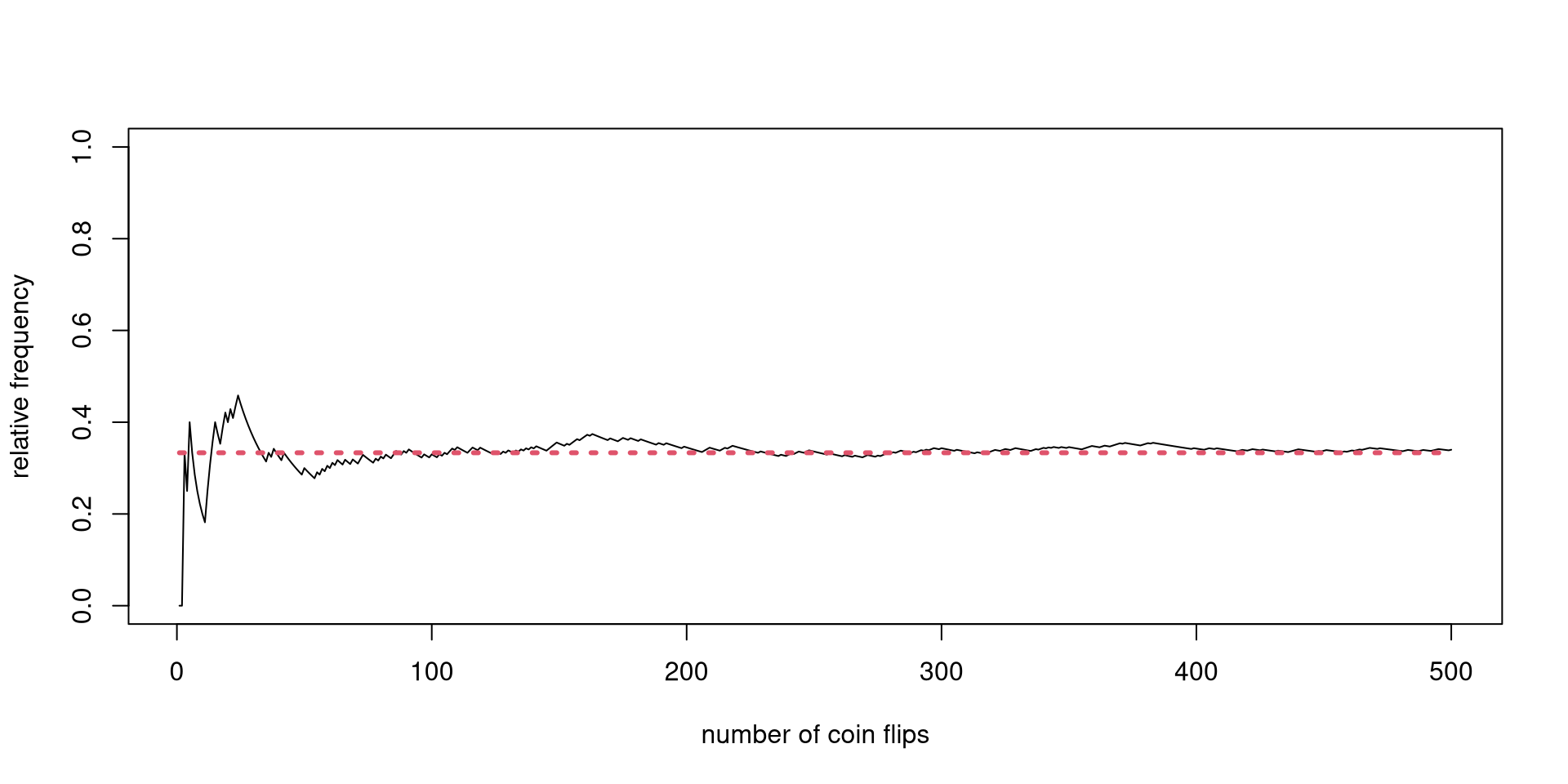
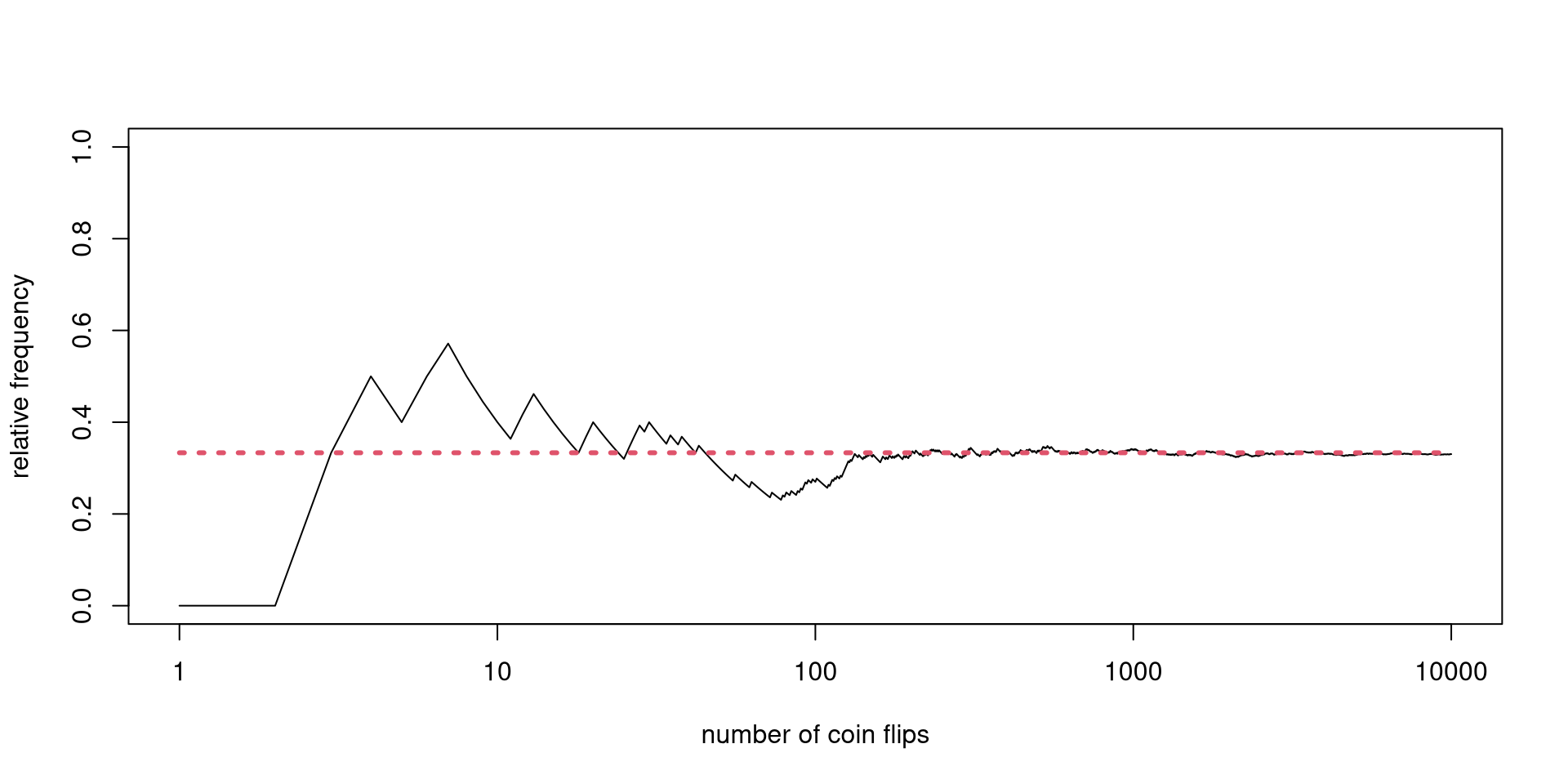
With enough observations of the act of coin tossing under similar conditions, a particular type of long-run behavior will emerge.
I will show an actual coin-tossing experiment and a simpler Monte Carlo simulation.
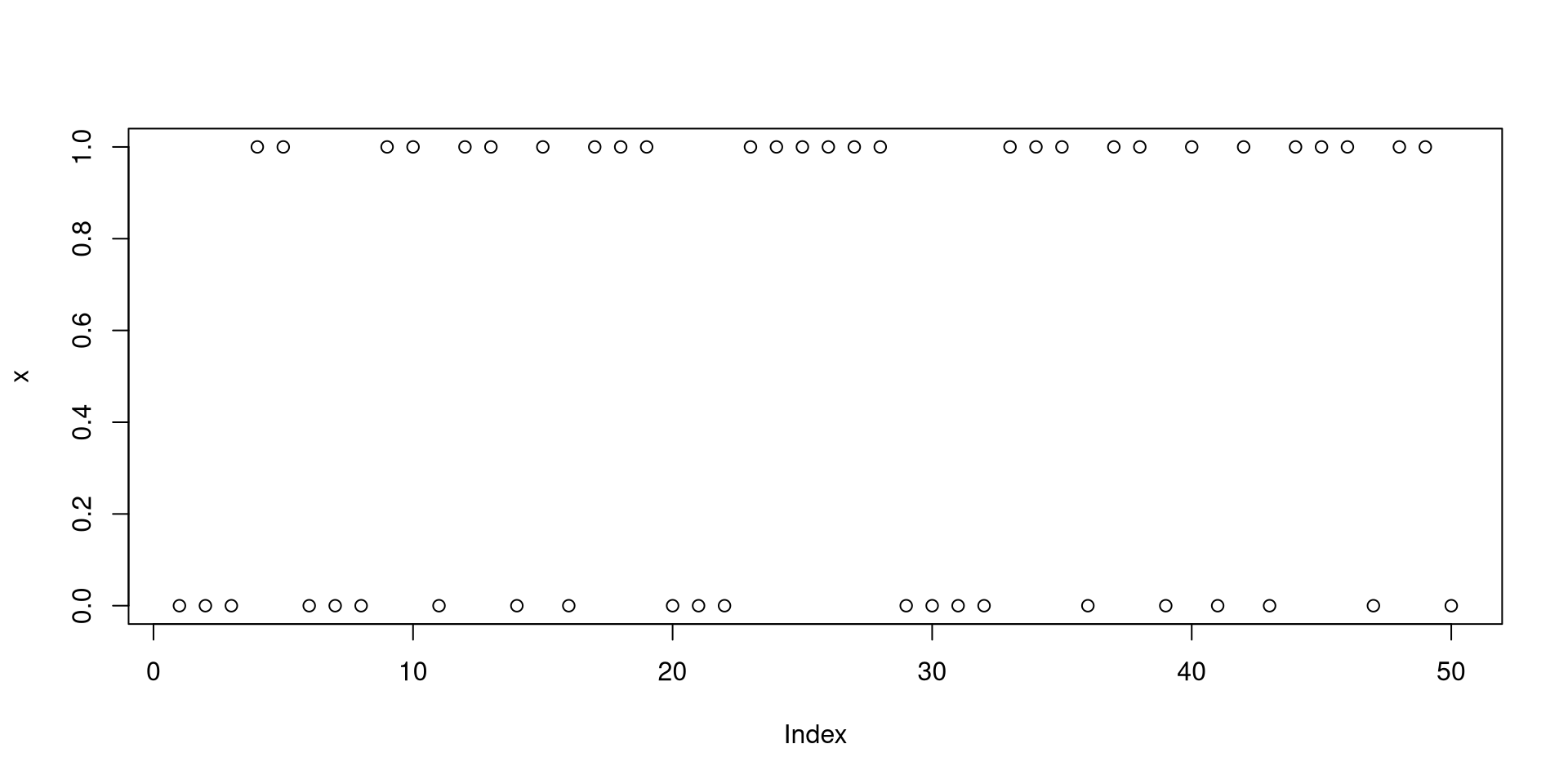
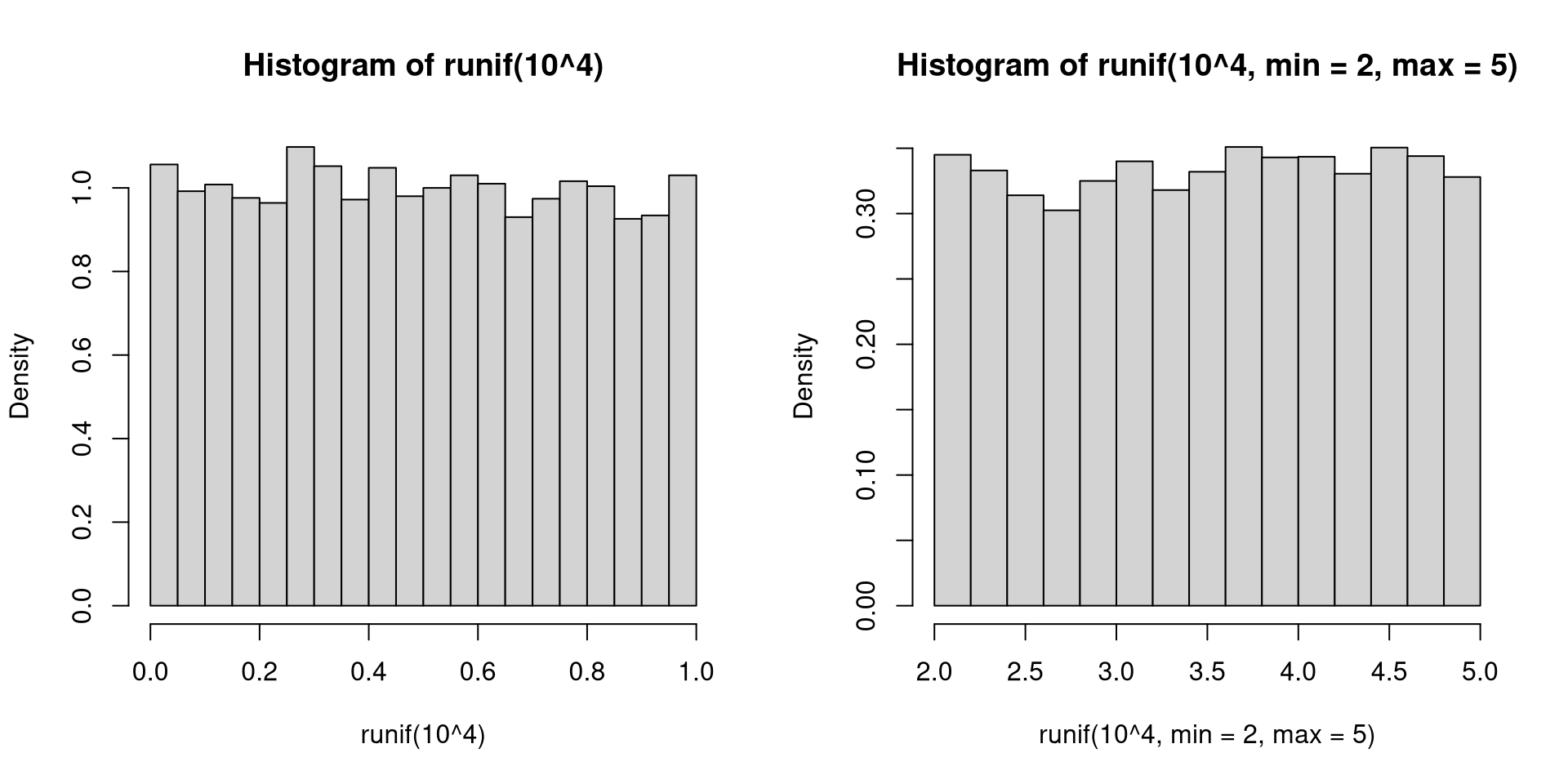
To toss a fair coin once: rbinom(1, 1, 0.5)
Assign \(n\) to 50: n <- 50
Toss a fair coin \(n\) times, and assign the outcomes to the object x: x <- rbinom(n, 1, 0.5)
Produce a plot of the object x: plot(x)
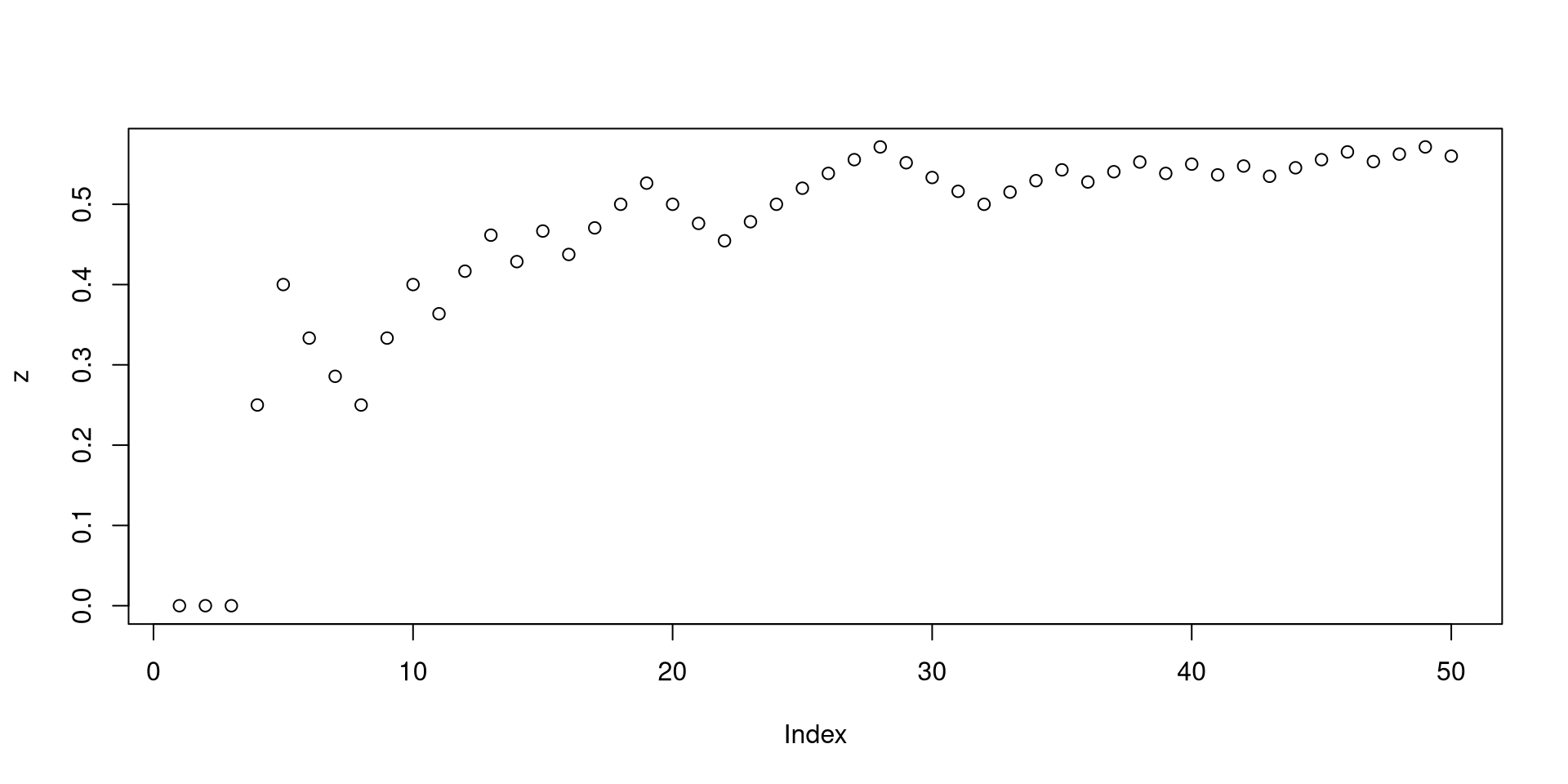
Calculate the relative frequency of heads, i.e., how many heads have been observed divided by how many tosses have been made: z <- cumsum(x)/(1:n)
Plot the relative frequency against tosses plot(z)
The results will be different for every computer.
Consider the tossing of a coin whether fair or not.
We are uncertain of the outcomes that will materialize for any specific coin toss.
Focusing on the mean, there is some form of order emerging in the long run.
BUT … there are terms and conditions, which you will learn in the course.
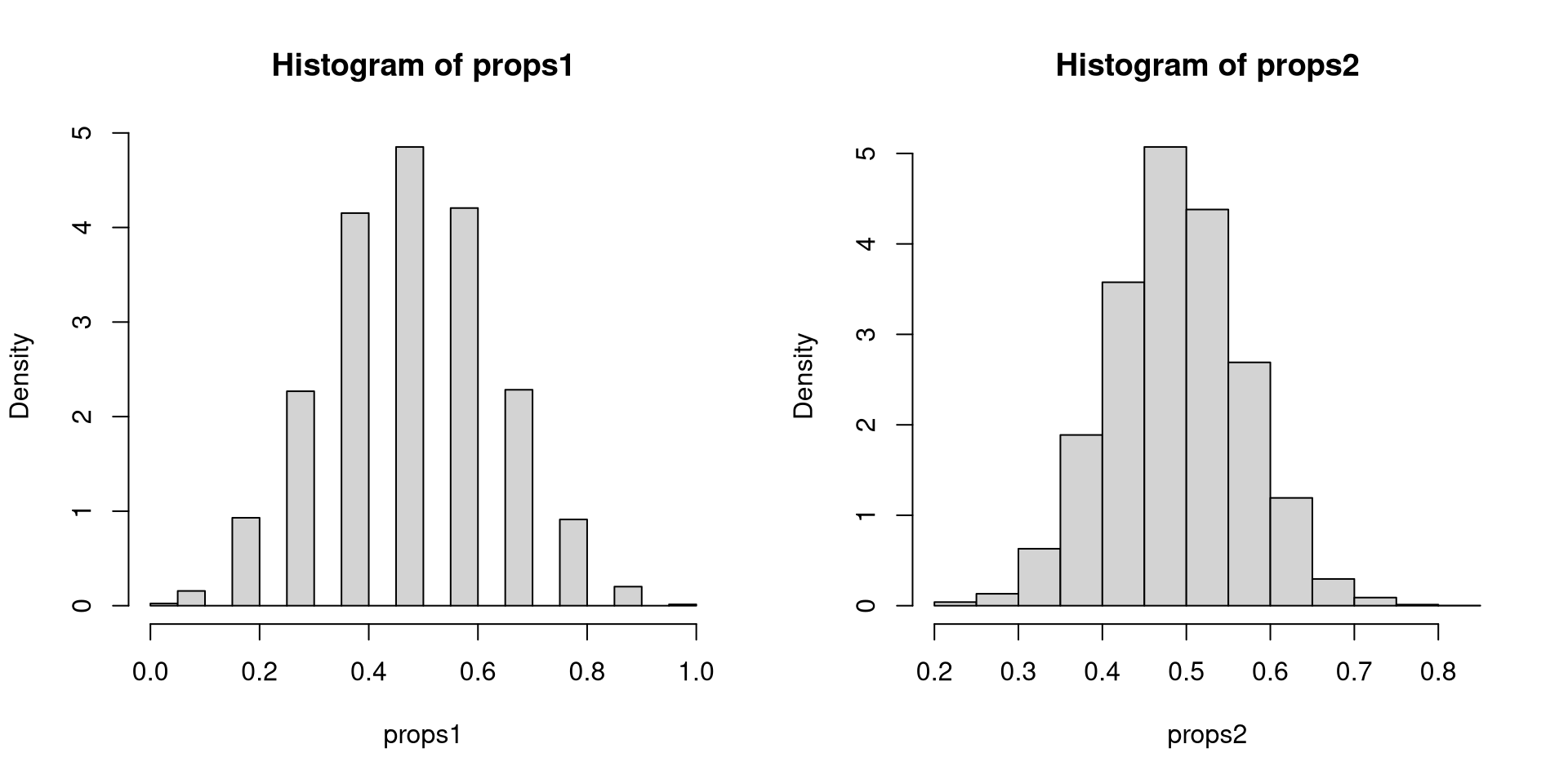
Set the number of repetitions: nsim <- 10^4
Repeat for nsim times “tossing of a fair coin 10 times”: set1 <- replicate(nsim, rbinom(10, 1, 0.5))
Calculate the relative frequency for every repetition: props1 <- colMeans(set1)
Visualize and summarize: hist(props1, freq=FALSE), table(props1)
nsim <- 10^4
set1 <- replicate(nsim, rbinom(10, 1, 0.5))
set2 <- replicate(nsim, rbinom(40, 1, 0.5))
props1 <- colMeans(set1)
props2 <- colMeans(set2)
table(props1)props1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
12 78 465 1134 2076 2426 2103 1142 456 101 7 [1] 0.5008300 0.1578379props2
0.225 0.25 0.275 0.3 0.325 0.35 0.375 0.4 0.425 0.45 0.475 0.5 0.525
4 16 16 50 121 194 359 585 781 1007 1227 1309 1177
0.55 0.575 0.6 0.625 0.65 0.675 0.7 0.725 0.75 0.775 0.825
1013 835 510 363 233 110 38 29 16 6 1 [1] 0.5001425 0.0795121nsim <- 10^4
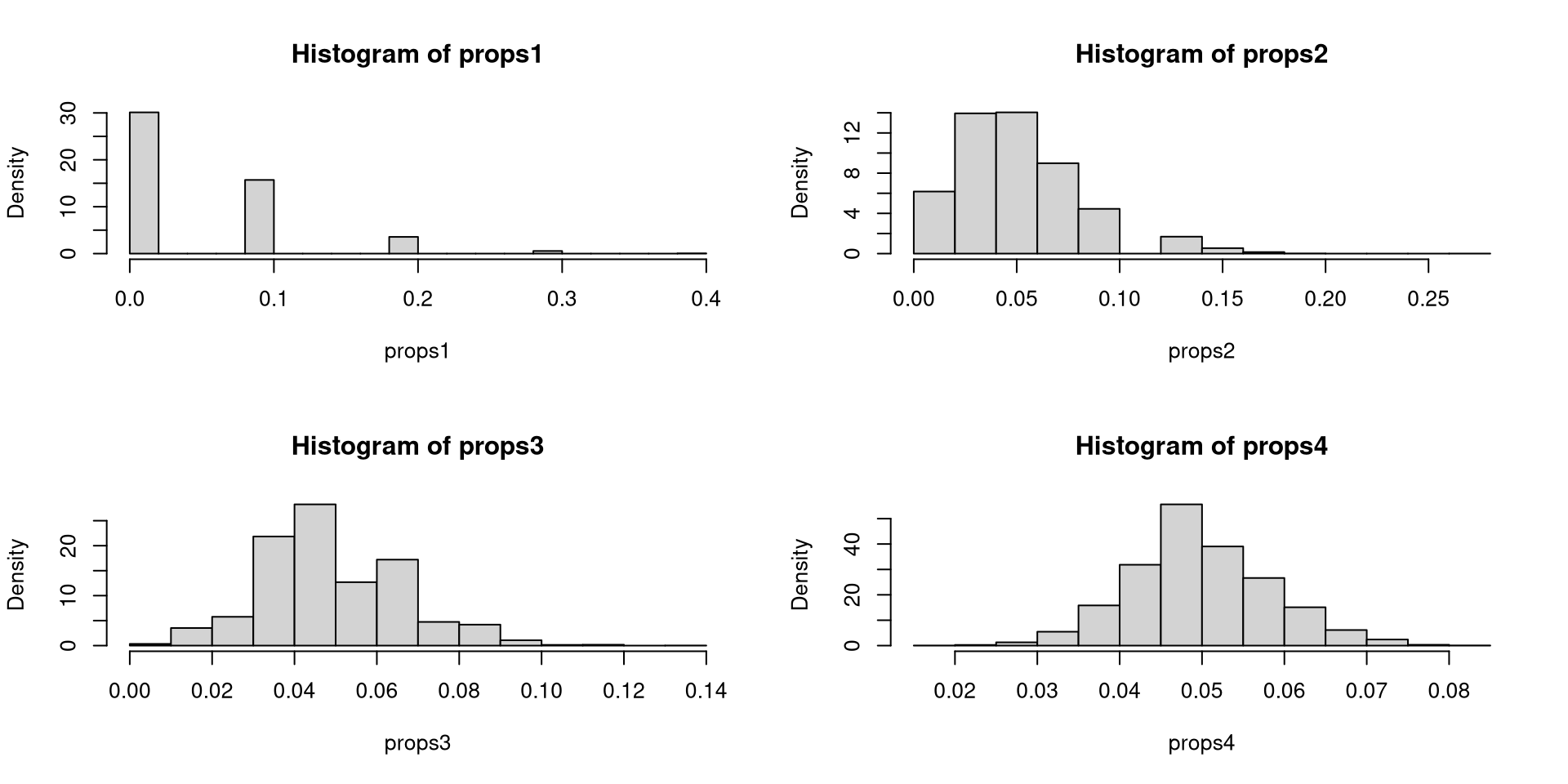
set1 <- replicate(nsim, rbinom(10, 1, 0.05))
set2 <- replicate(nsim, rbinom(40, 1, 0.05))
set3 <- replicate(nsim, rbinom(160, 1, 0.05))
set4 <- replicate(nsim, rbinom(640, 1, 0.05))
props1 <- colMeans(set1)
props2 <- colMeans(set2)
props3 <- colMeans(set3)
props4 <- colMeans(set4)
c(mean(props1), sd(props1))[1] 0.04946000 0.06874723[1] 0.04984750 0.03426779[1] 0.04973000 0.01722019[1] 0.04990359 0.00855110# Number of observations
n <- 50
# How many times to loop
reps <- 10^4
# Storage for OLS results (2 entries per replication)
beta.store <- matrix(NA, nrow=reps, ncol=2)
# Monte Carlo loop
for (i in 1:reps)
{
X.t <- rbinom(n, 1, 0.3) # Generate X
eps.t <- (rnorm(n, 0, 4))*(X.t == 1)+(rnorm(n, 0, 1))*(X.t == 0)
Y.t <- 3 + 2*X.t + eps.t # Generate Y
temp <- lm(Y.t ~ X.t)
beta.store[i,] <- coef(temp)
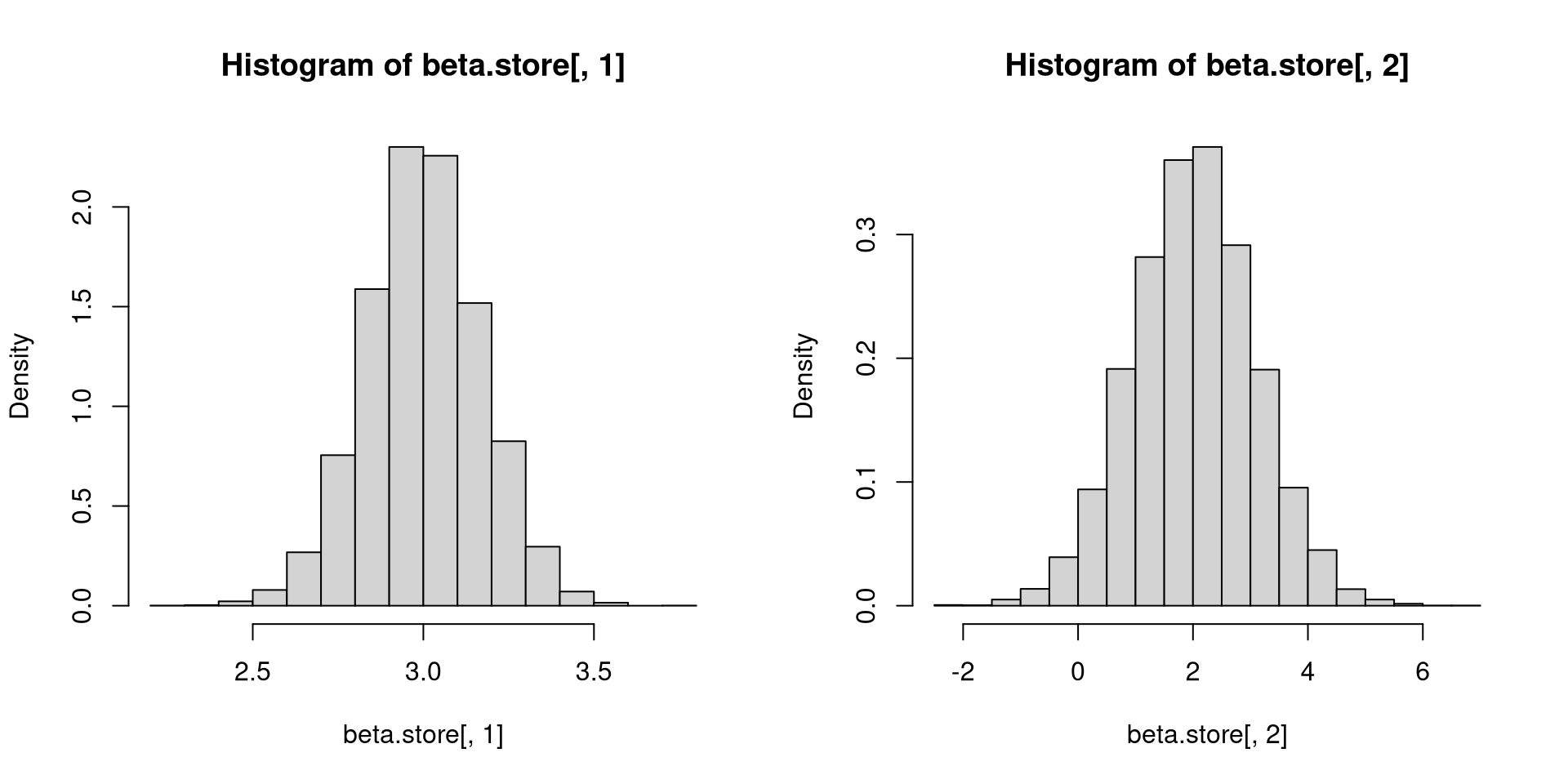
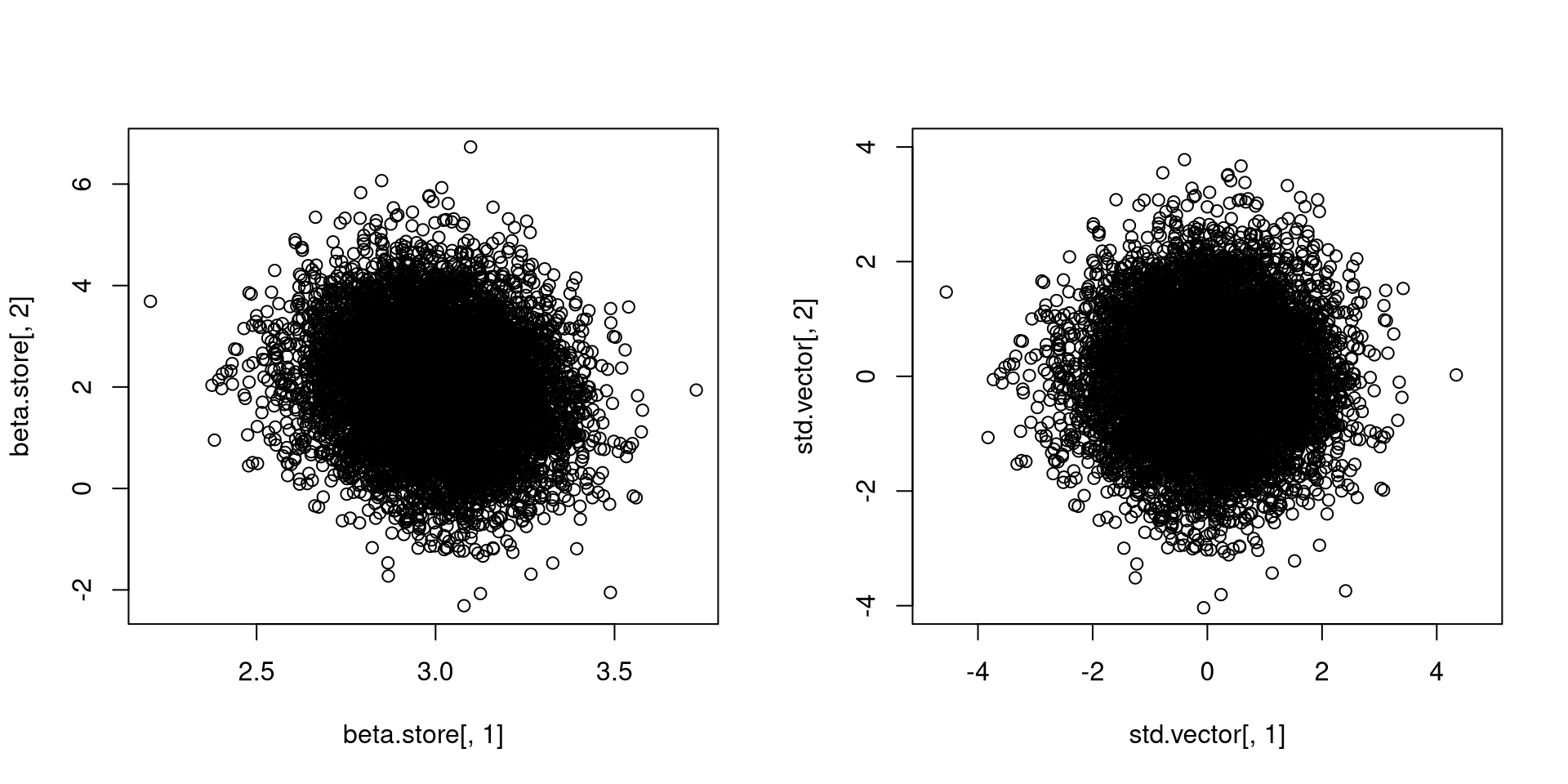
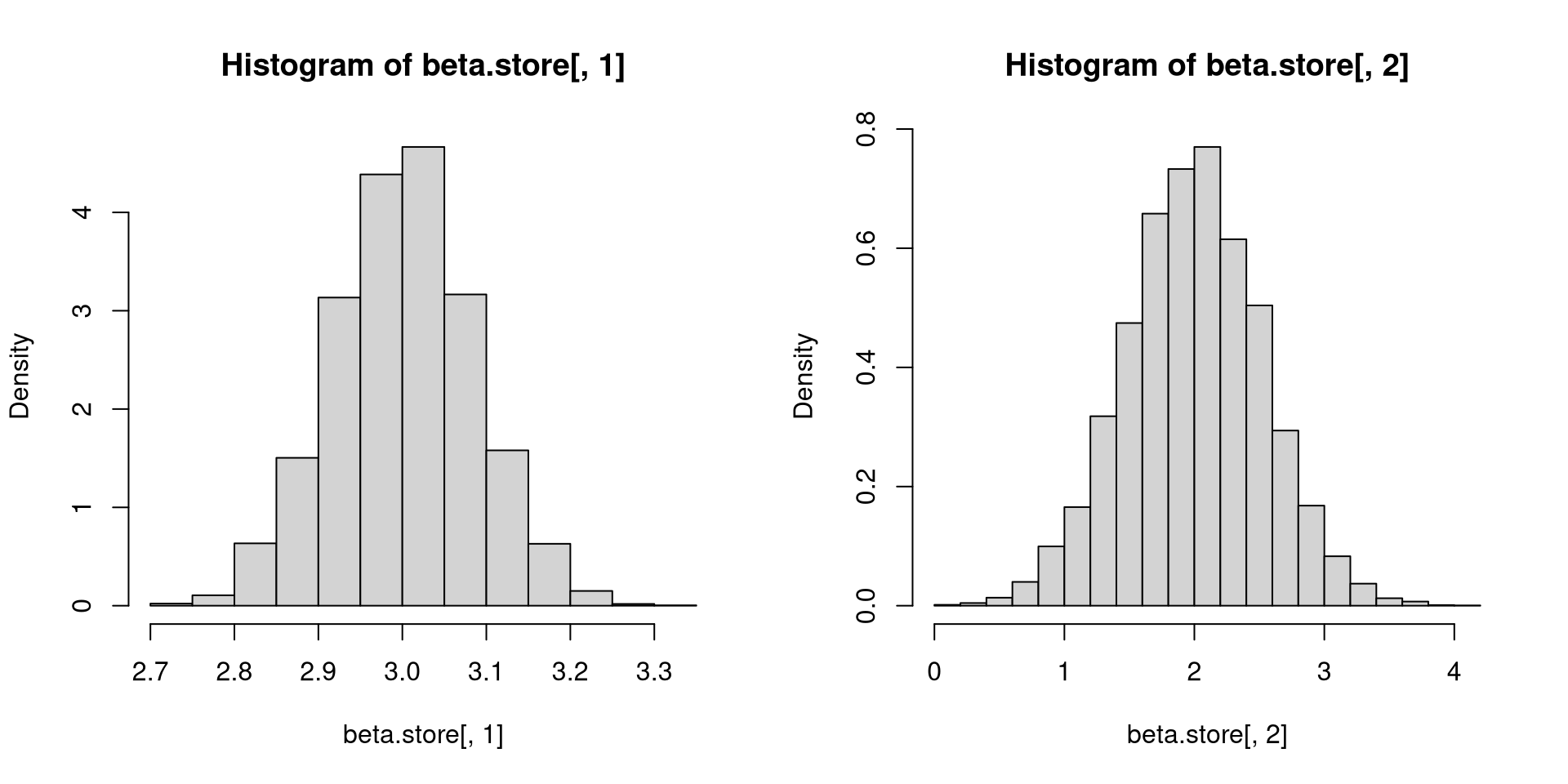
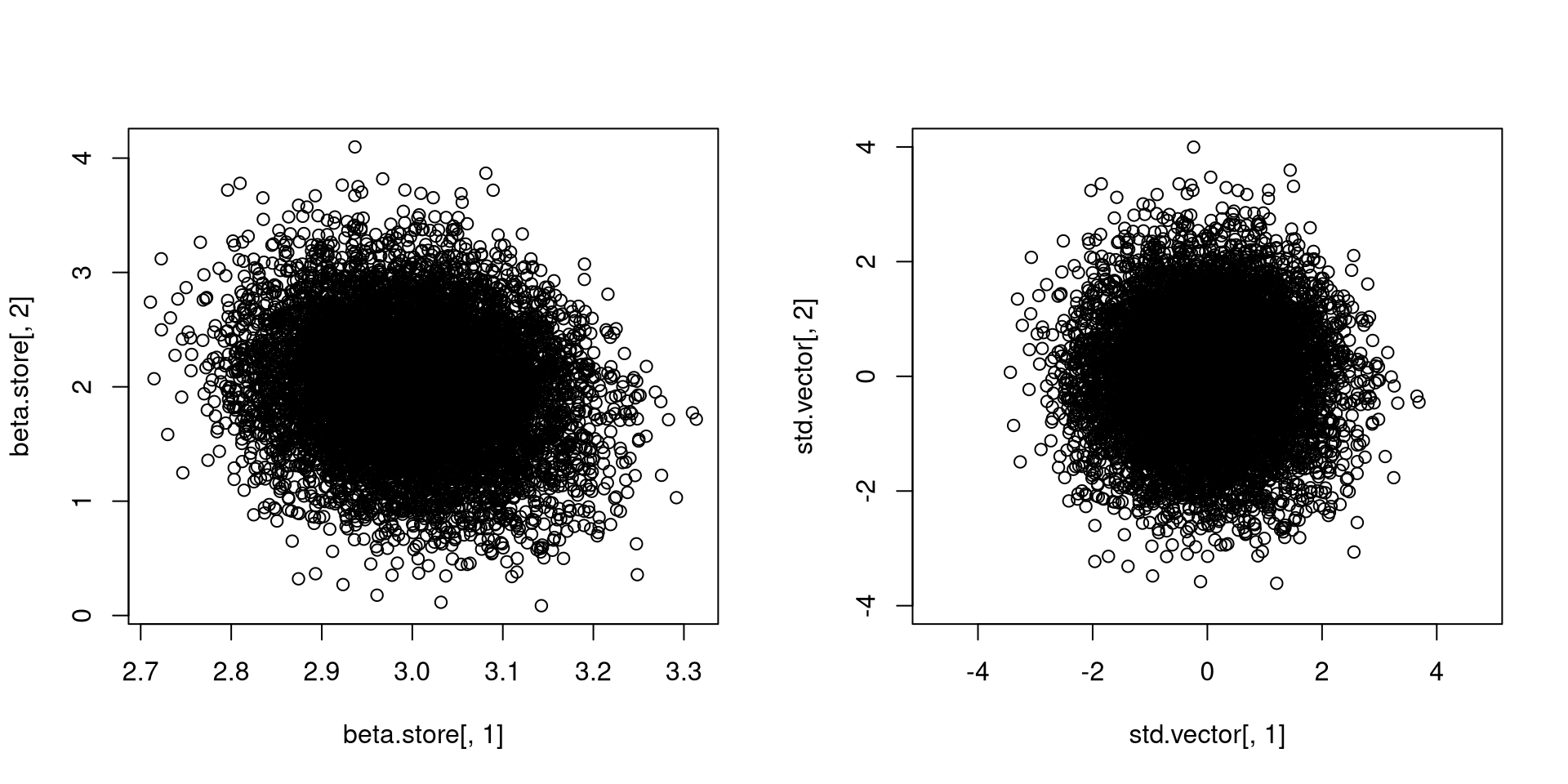
}[1] 3.000454 2.011697[1] 0.1693322 1.0718008evalues <- eigen(cov(beta.store))$values
evectors <- eigen(cov(beta.store))$vectors
std.vector <- (beta.store - cbind(rep(mean(beta.store[,1]), reps), rep(mean(beta.store[,2]), reps))) %*% (evectors %*% diag(1/sqrt(evalues)) %*% t(evectors))
par(mfrow=c(1,2))
plot(beta.store[,1], beta.store[,2])
plot(std.vector[,1], std.vector[,2], asp = 1, xlim = c(-4, 4), ylim = c(-4, 4)) [,1] [,2]
[1,] 0.02867338 -0.02763096
[2,] -0.02763096 1.14875696 [,1] [,2]
[1,] 1.000000e+00 1.061363e-17
[2,] 1.061363e-17 1.000000e+00# Number of observations
n <- 200
# How many times to loop
reps <- 10^4
# Storage for OLS results (2 entries per replication)
beta.store <- matrix(NA, nrow=reps, ncol=2)
# Monte Carlo loop
for (i in 1:reps)
{
X.t <- rbinom(n, 1, 0.3) # Generate X
eps.t <- (rnorm(n, 0, 4))*(X.t == 1)+(rnorm(n, 0, 1))*(X.t == 0)
Y.t <- 3 + 2*X.t + eps.t # Generate Y
temp <- lm(Y.t ~ X.t)
beta.store[i,] <- coef(temp)
}[1] 3.001431 1.995479[1] 0.08398259 0.52551020You are seeing how the procedure behind lm(), which is really calculating regression coefficients, is behaving in different artificial datasets.
lm() involves functions of averages!Of course, these artificial datasets are generated from the same population, or that they are governed by the same data generating process (DGP).
Pay attention to the axes and what role standardization plays.
It means that some operations we apply to the data may have some long-run properties, even though there is some variability ever present in data.
In particular, the mean is such an important empirical quantity which has some long-run regularity.
This motivates us to use the mean in practice.
The question is what is the mean converging to?
We need to introduce the following new concepts:
We introduced \(X_t\) as taking value equal to 1 if the \(t\)th coin toss produces heads, and 0 otherwise.
\(X_t\) maps from where to where?
Here we have, \(X_t\left(\mathrm{Heads}\right)=1\) and \(X_t\left(\mathrm{Tails}\right)=0\).
The sample space here is \(\Omega=\{1,2,3,4,5,6\}\).
Since we are interested in the outcome of the die roll, we can define a random variable \(X_t\) to be equal to the value from the \(t\)th die roll.
To specify this function, we can write \(X_t\left(\omega\right)=\omega\) for \(\omega\in\Omega\).
Of course, how we label this sample space should not matter, but your random variable would have to be tweaked somehow.
In our coin toss example, there seems to be convergence of the mean to some quantity.
We are now going to build this quantity, which is called the expectation or expected value.
Since the mean (as we calculate it) has to satisfy some natural properties, it is hard to argue against wanting to endow the expectation with the same properties.
We are now going to define an operator called the expectation operator, denoted by \(\mathbb{E}\left(\cdot\right)\). This operator is a rule which assigns a scalar random variable \(X\) to a number \(\mathbb{E}\left(X\right)\), but this rule has to satisfy the following axioms:
Axioms are statements which we take to be true, but is compatible with our experience.
The axioms by themselves do NOT tell you how to actually calculate an expectation!
A useful consequence of the axioms is that: \[\mathbb{E}\left(\sum_{j=1}^n c_jX_j\right)=\sum_{j=1}^n c_j \mathbb{E}\left(X_j\right)\]
Do note that it is possible for \(\mathbb{E}\left(X\right)\) to actually not exist. We will encounter this later, as this arises in practice.
From the axioms, we can also derive a definition for the probability of an event \(A\).
\(I\left(A\right)\) is called an indicator random variable.
We will not spend so much time calculating probabilities. In fact, the presentation is a bit nontraditional.
Suppose \(\Omega=\{\omega_1,\ldots,\omega_K\}\), a finite sample space.
Let \(X\) be a random variable defined on this sample space.
In this context, \(X\) is a discrete random variable.
Based on the axioms, the expectation can be shown to be equal to \[\mathbb{E}\left(X\right)=\sum_{k=1}^K p_kX\left(\omega_k\right)\] with \(p_k=\mathbb{P}\left(\omega_k\right)\), where \(p_1,\ldots,p_K\) has to be constrained as follows:
For a coin toss, \[\begin{eqnarray}\mathbb{E}\left(X_t\right) &=&\mathbb{P}\left(\mathrm{Heads}\right)*X_t\left(\mathrm{Heads}\right)+\mathbb{P}\left(\mathrm{Tails}\right)*X_t\left(\mathrm{Tails}\right)\\ &=&\mathbb{P}\left(\mathrm{Heads}\right)\end{eqnarray}\]
For a die roll, \[\begin{eqnarray}\mathbb{E}\left(X\right) &=&\mathbb{P}\left(1\right)*X\left(1\right)+\mathbb{P}\left(2\right)*X\left(2\right)+\mathbb{P}\left(3\right)*X\left(3\right)\\ &&+ \mathbb{P}\left(4\right)*X\left(4\right)+\mathbb{P}\left(5\right)*X\left(5\right)+\mathbb{P}\left(6\right)*X\left(6\right)\\ &=& \mathbb{P}\left(1\right)*1+\mathbb{P}\left(2\right)*2+\mathbb{P}\left(3\right)*3\\ &&+ \mathbb{P}\left(4\right)*4+\mathbb{P}\left(5\right)*5+\mathbb{P}\left(6\right)*6\end{eqnarray}\]
Notice that you need probabilities to be able to calculate and simplify these expectations.
These probability assignments have to obey the conditions indicated earlier. These probability assignments form a discrete probability distribution for a random variable.
If the coin is fair, then the discrete probability distribution for \(X_t\) is given by \(\mathbb{P}\left(\mathrm{Heads}\right)=1/2\) and \(\mathbb{P}\left(\mathrm{Tails}\right)=1/2\).
If the die is fair, then the discrete probability distribution for \(X\) is given by \(\mathbb{P}\left(i\right)=1/6\) for all \(i=1,2,3,4,5,6\).
You can definitely dream up other discrete probability distributions for a coin or a die roll, provided that you satisfy the conditions.
This may not feel practically relevant but having infinitely many values can be a good approximation to the case of having a very large value of \(K\).
Setting of thought experiment:
The thought experiment:
What will change is that the summation found in the expectation is replaced by an integral, i.e., \[\mathbb{E}\left(X\right)=\int_{-\infty}^{\infty} X\left(\omega\right)f\left(\omega\right)\,\,d\omega\] provided that this integral exists.
Just like the discrete case, there would be constraints on \(f\) which will guarantee that \(\mathbb{E}\left(X\right)\) satisfies the axioms.
In particular, \(f\) should satisfy:
\(f\) is called a probability density on \(\Omega\). \(X\) has a continuous probability distribution on \(\Omega\).
You are not expected to know how to explicitly calculate expectations of random variables having continuous probability distributions if you are given \(f\). Integration skills are needed for this.
Probabilities and probability densities are different from each other but are related.
Their empirical counterparts are relative frequencies and relative frequency per unit.
When we talked about histograms, we talked about two different ways of presenting them.
You can show that \(\mathsf{Var}\left(X\right)=\mathbb{E}\left(X^2\right)-\mathbb{E}\left(X\right)^2\).
Interestingly, we have \[\mathsf{Var}\left(X\right)=\min_{c}\mathbb{E}\left[\left(X-c\right)^2\right]\]
The standard deviation of a random variable \(X\) is given by \(\sqrt{\mathsf{Var}\left(X\right)}\).
You have to wonder whether the standard deviation you have seen before is somewhat related to the standard deviation of a random variable.
We can also form the standardized version of a random variable \(X\). What do you think it would look like?
There are higher-order moments which are used in practice, but not as much as the first two moments.
The third and fourth moments of \(X\) are related to symmetry and tail behavior of the distribution of the random variable \(X\).
Everything we have done could (more or less) be extended to the case of multiple random variables.
Moments for random vectors are less straightforward. For our purposes, I will be explicit about these as we go along.
The covariance of two random variables \(X\) and \(Y\) is defined as: \[\begin{eqnarray}\mathsf{Cov}\left(X,Y\right) &=& \mathbb{E}\left[\left(X-\mathbb{E}\left(X\right)\right)\left(Y-\mathbb{E}\left(Y\right)\right)\right]\\ &=&\mathbb{E}\left(XY\right)-\mathbb{E}\left(Y\right)\mathbb{E}\left(X\right)\end{eqnarray}\]
The correlation coefficient of two random variables \(X\) and \(Y\) is defined as: \[\rho_{X,Y} = \frac{\mathsf{Cov}\left(X,Y\right)}{\sqrt{\mathsf{Var}\left(X\right)\mathsf{Var}\left(Y\right)}}\]
This application is based on Gelman and Nolan (2009).
Suppose you have two coin sequences (heads is 1, tails is 0):
Sequence A: 0011100011/0010000100/0010001000/1000000001/0011001010
1100001111/1100110001/0101100100/1000100000/0011111001
Sequence B: 0100010100/1100010100/1110100110/0011110100/0111010001
1000110111/1000100101/1011011100/0110010001/0010000100
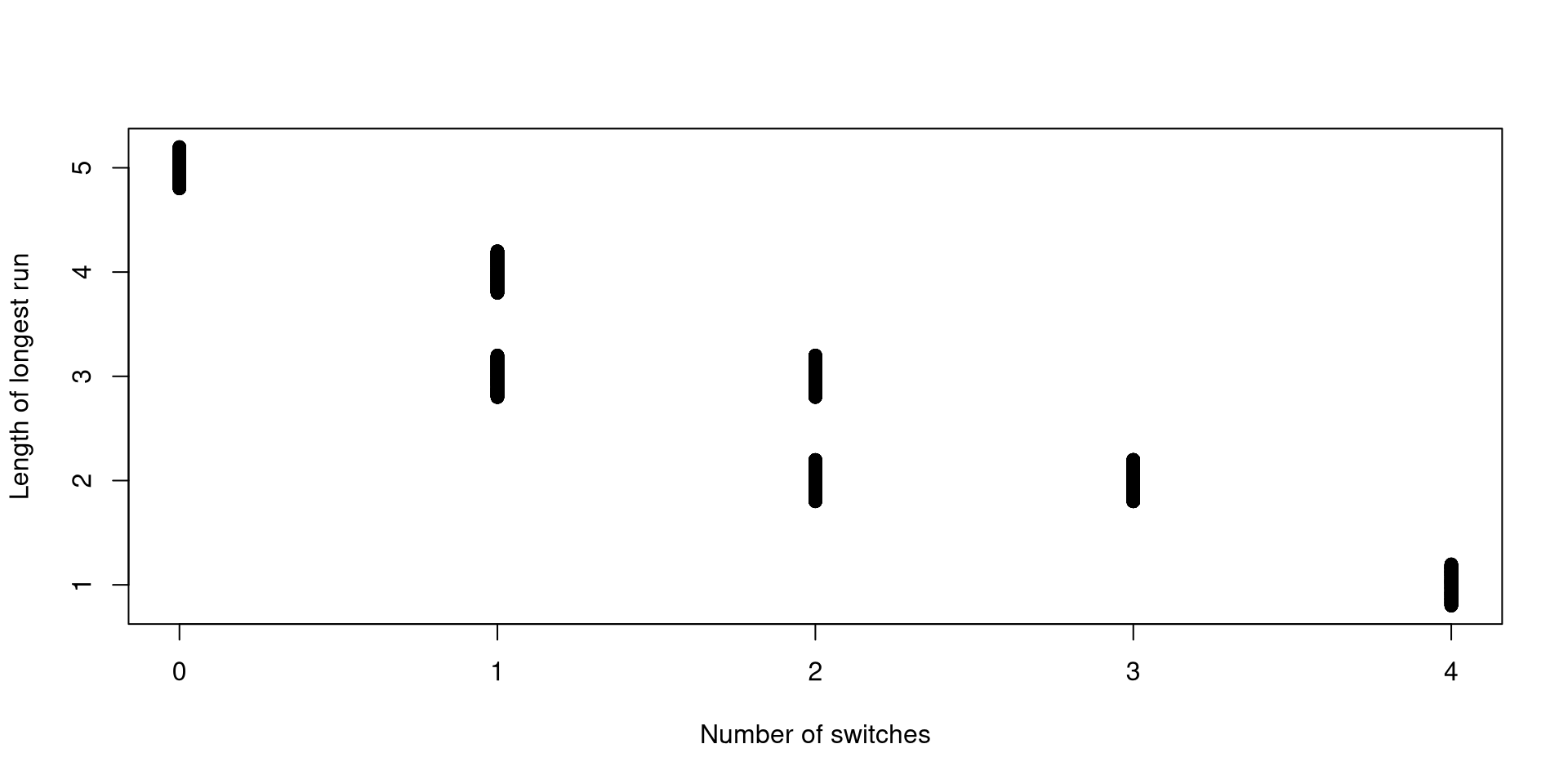
As a starting point, flip a coin 5 times. Assume that the outcomes of those three coins are equally likely to occur. Define
\(Y\) to be the length of the longest run (run = a sequence of consecutive flips of the same type)
\(X\) to be the number of switches from heads to tails or tails to heads
What is \(\mathsf{Cov}\left(X,Y\right)\) for this special case?
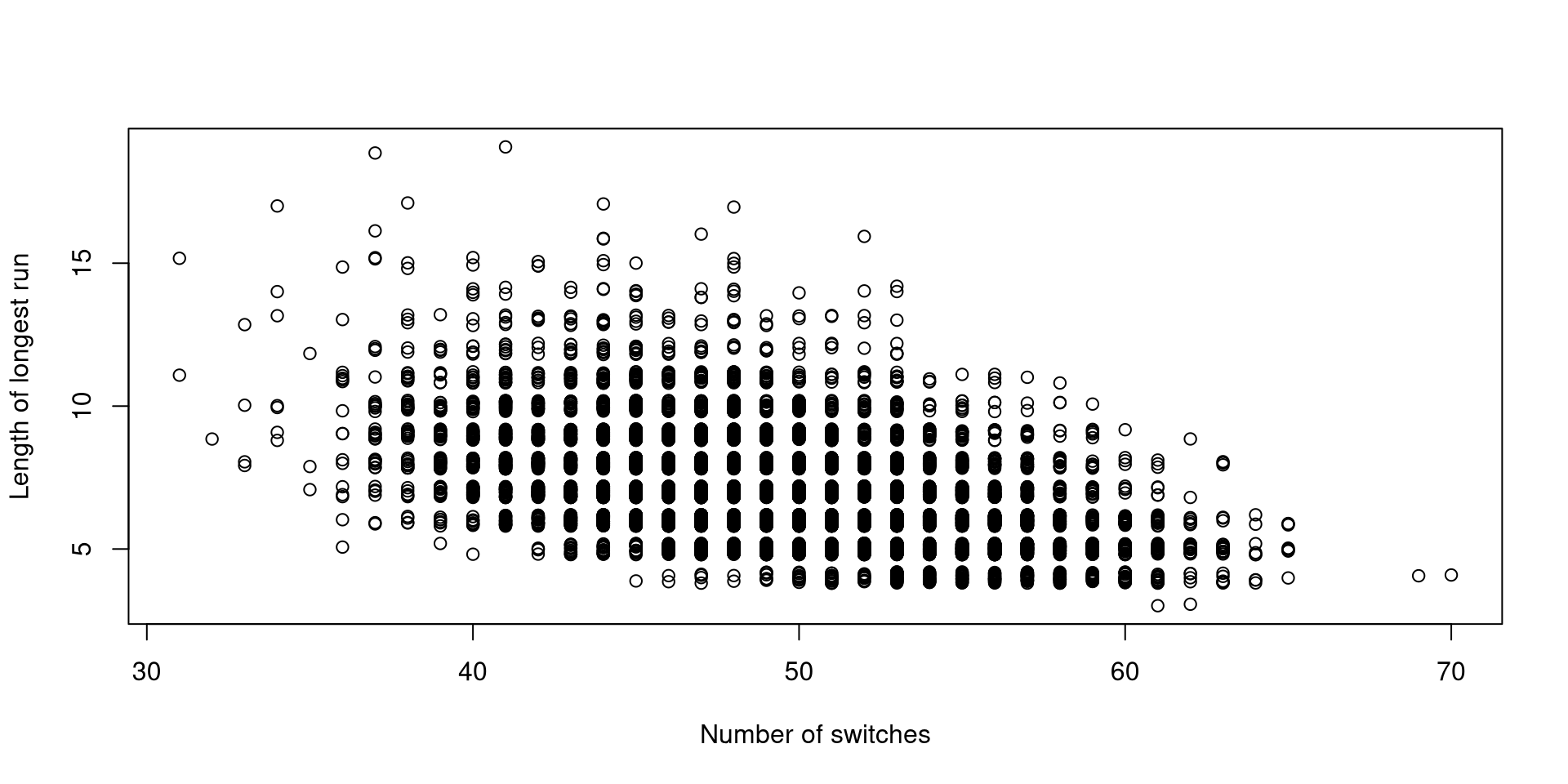
What happens when you have more than 5 tosses – say 100 tosses? Simulation might be easier here!
x <- rbinom(50000, 1, 0.5); x <- matrix(x, nrow = 10000)
result <- apply(x, 1, rle)
dist <- matrix(rep(0,nrow(x)*2), ncol=2)
for(i in 1:nrow(x))
{
temp <- result[[i]]$lengths
dist[i,]<-c(length(temp)-1, max(temp))
}
plot(dist[,1], jitter(dist[, 2], 1), xlab="Number of switches", ylab="Length of longest run") [,1] [,2]
[1,] 0.9969957 -0.8700902
[2,] -0.8700902 0.9563804 [,1] [,2]
[1,] 1.0000000 -0.8910505
[2,] -0.8910505 1.0000000What if we have 100 flips?
x <- rbinom(1000000, 1, 0.5); x <- matrix(x, nrow = 10000)
result <- apply(x, 1, rle)
dist <- matrix(rep(0,nrow(x)*2), ncol=2)
for(i in 1:nrow(x))
{
temp <- result[[i]]$lengths
dist[i,]<-c(length(temp)-1, max(temp))
}
plot(dist[,1], jitter(dist[, 2], 1), xlab="Number of switches", ylab="Length of longest run") [,1] [,2]
[1,] 25.056895 -4.079916
[2,] -4.079916 3.167407 [,1] [,2]
[1,] 1.0000000 -0.4579686
[2,] -0.4579686 1.0000000Experiments resulting in “success” or “failure” but not both
You have to define what “success” means and ensure that “failure” is the complement.
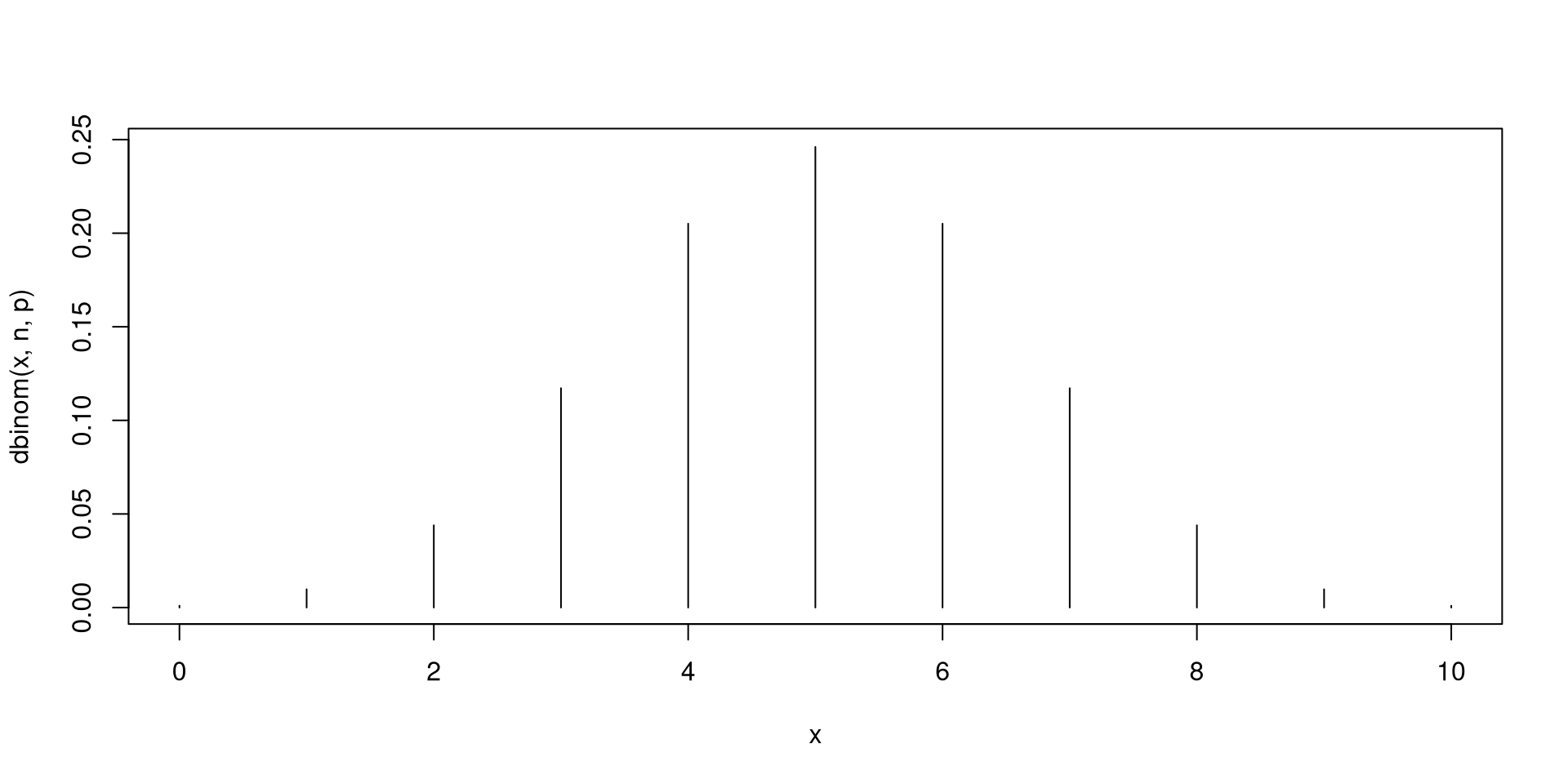
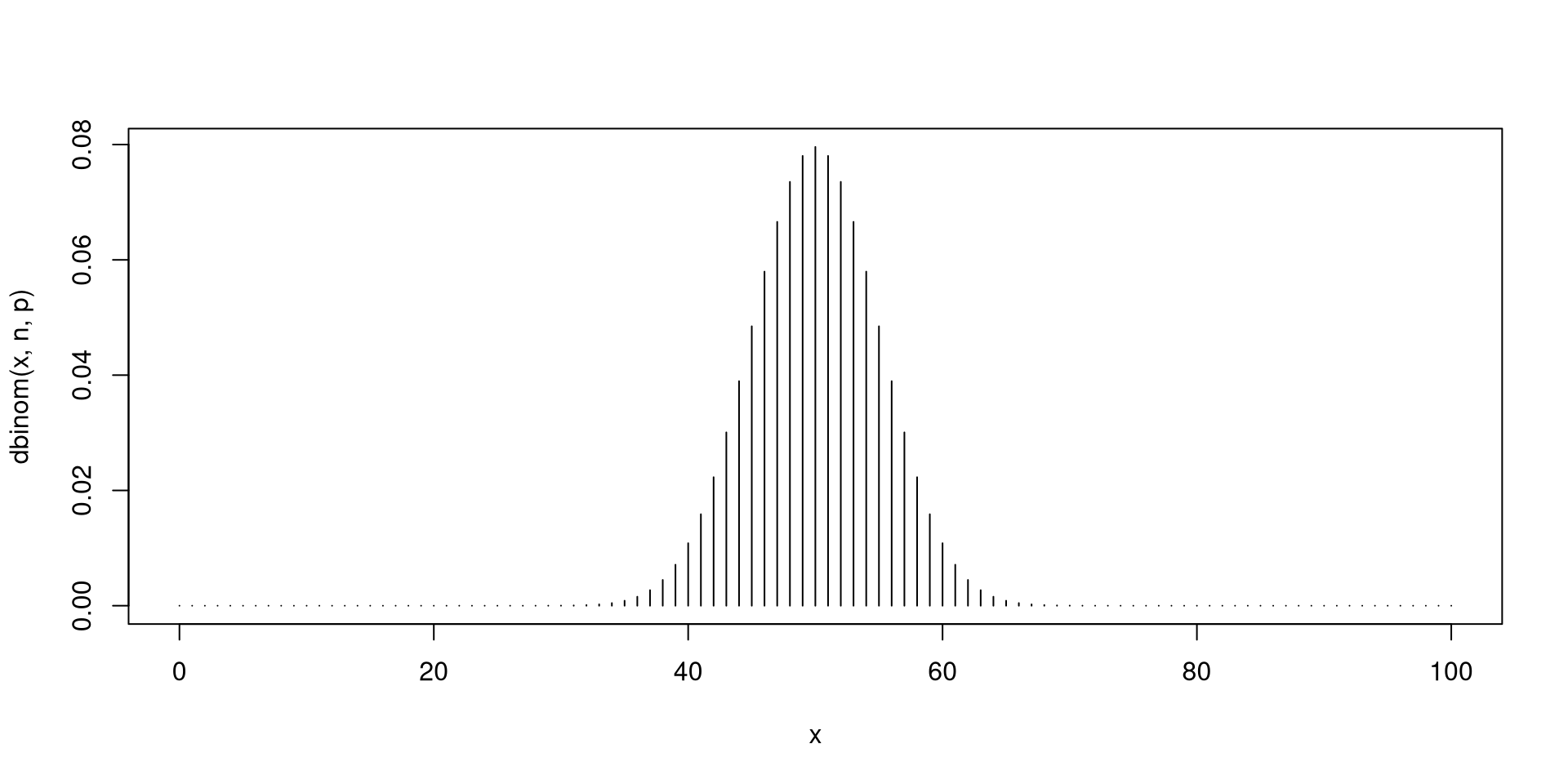
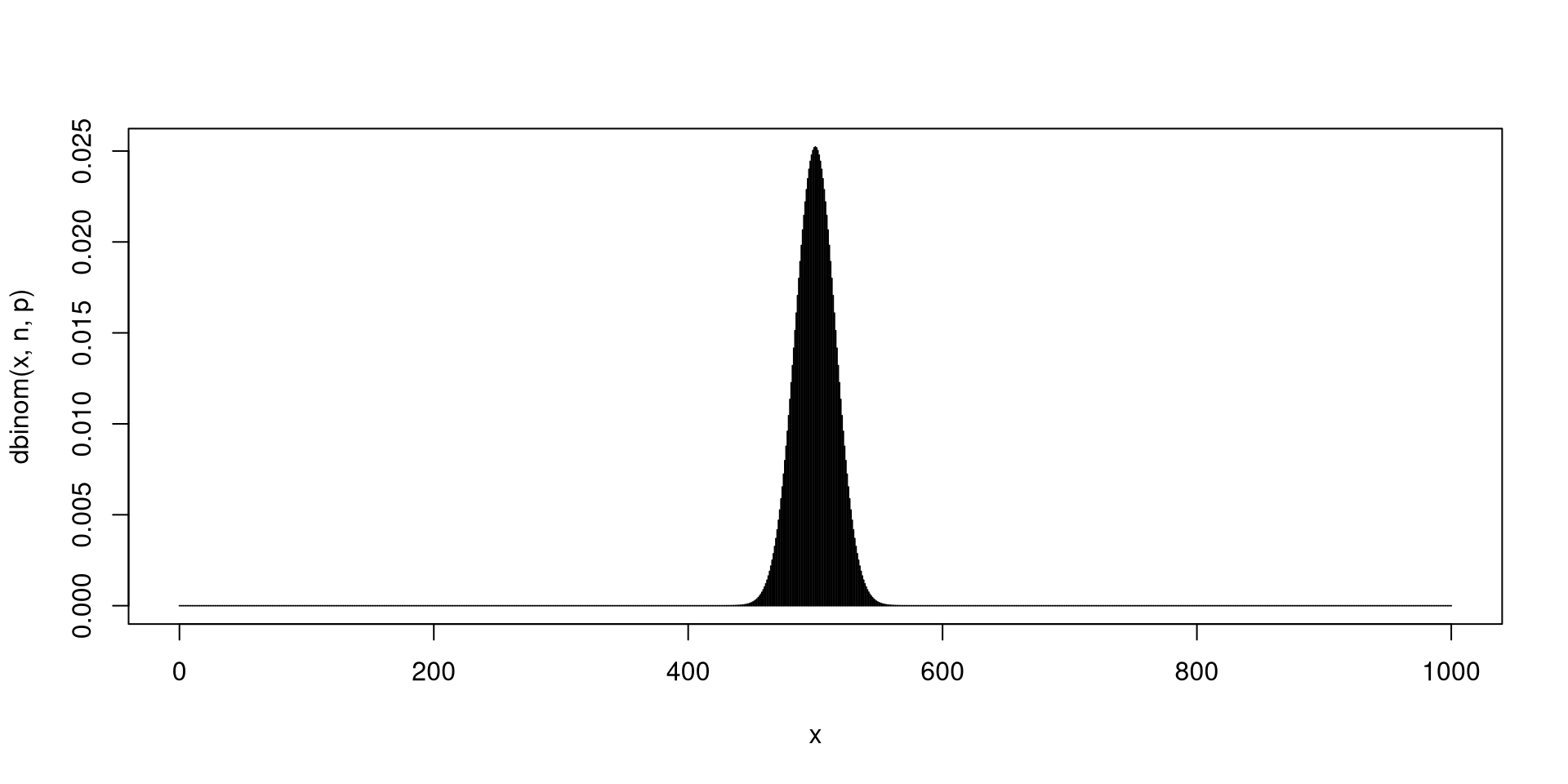
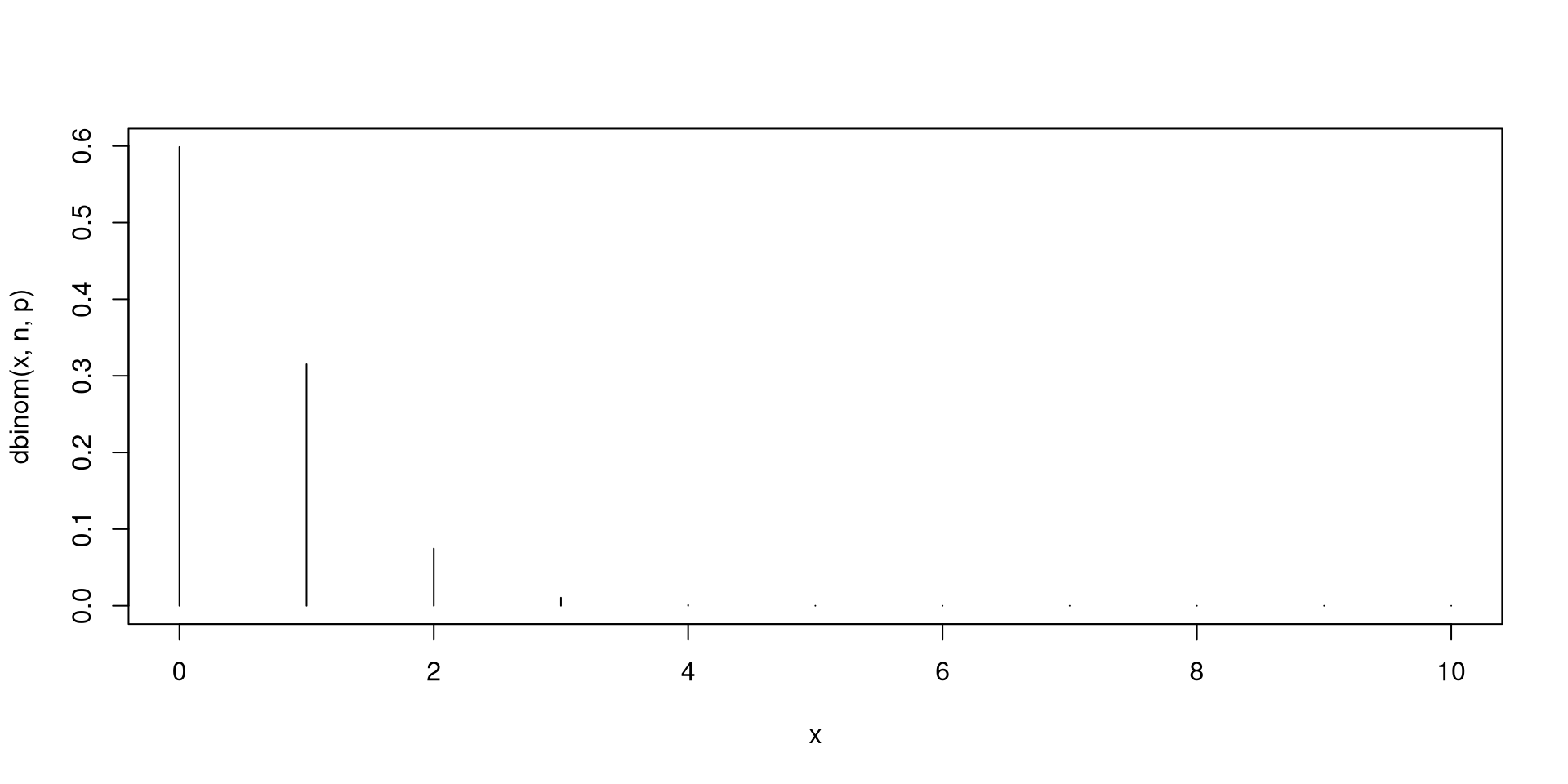
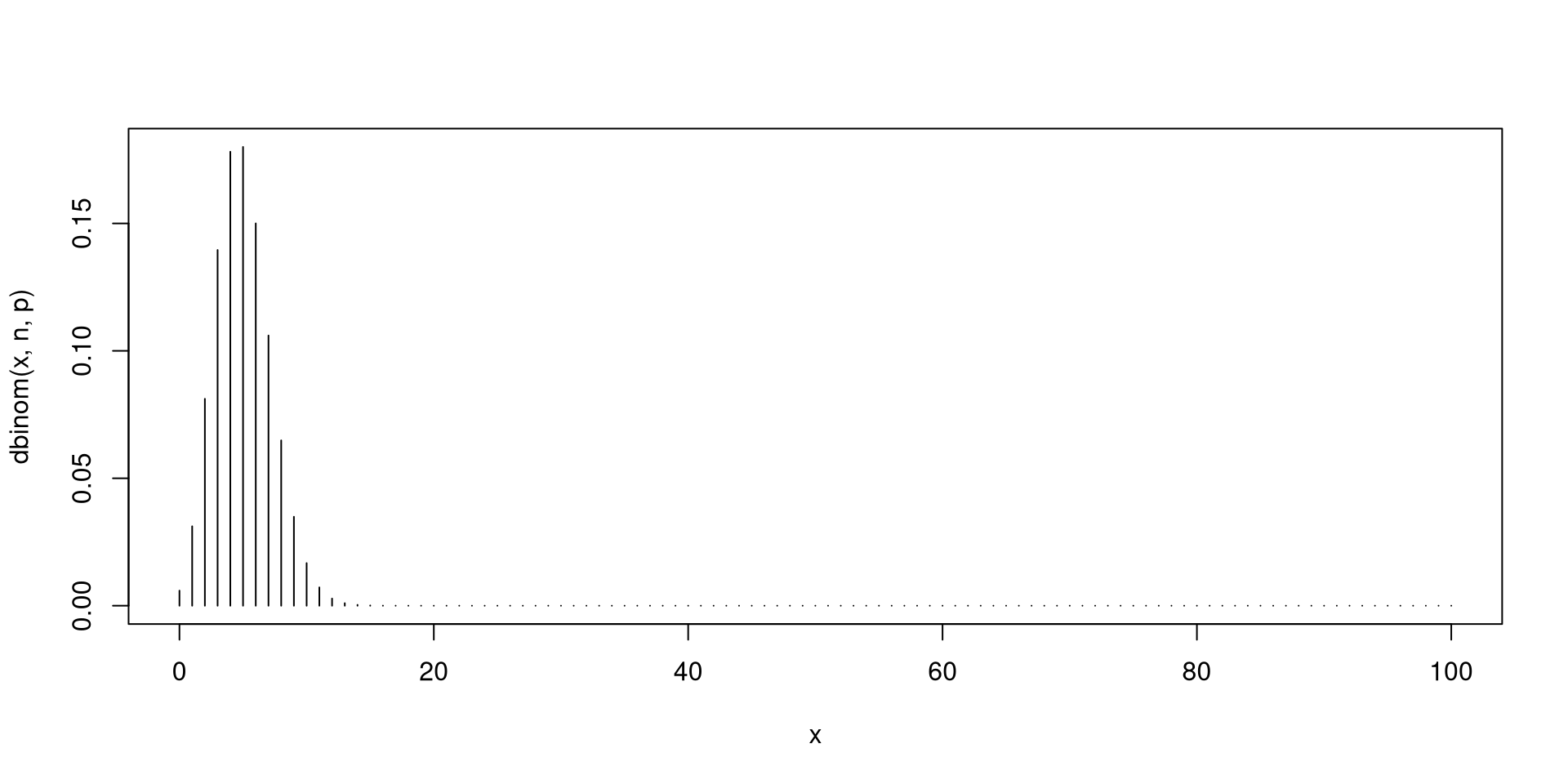
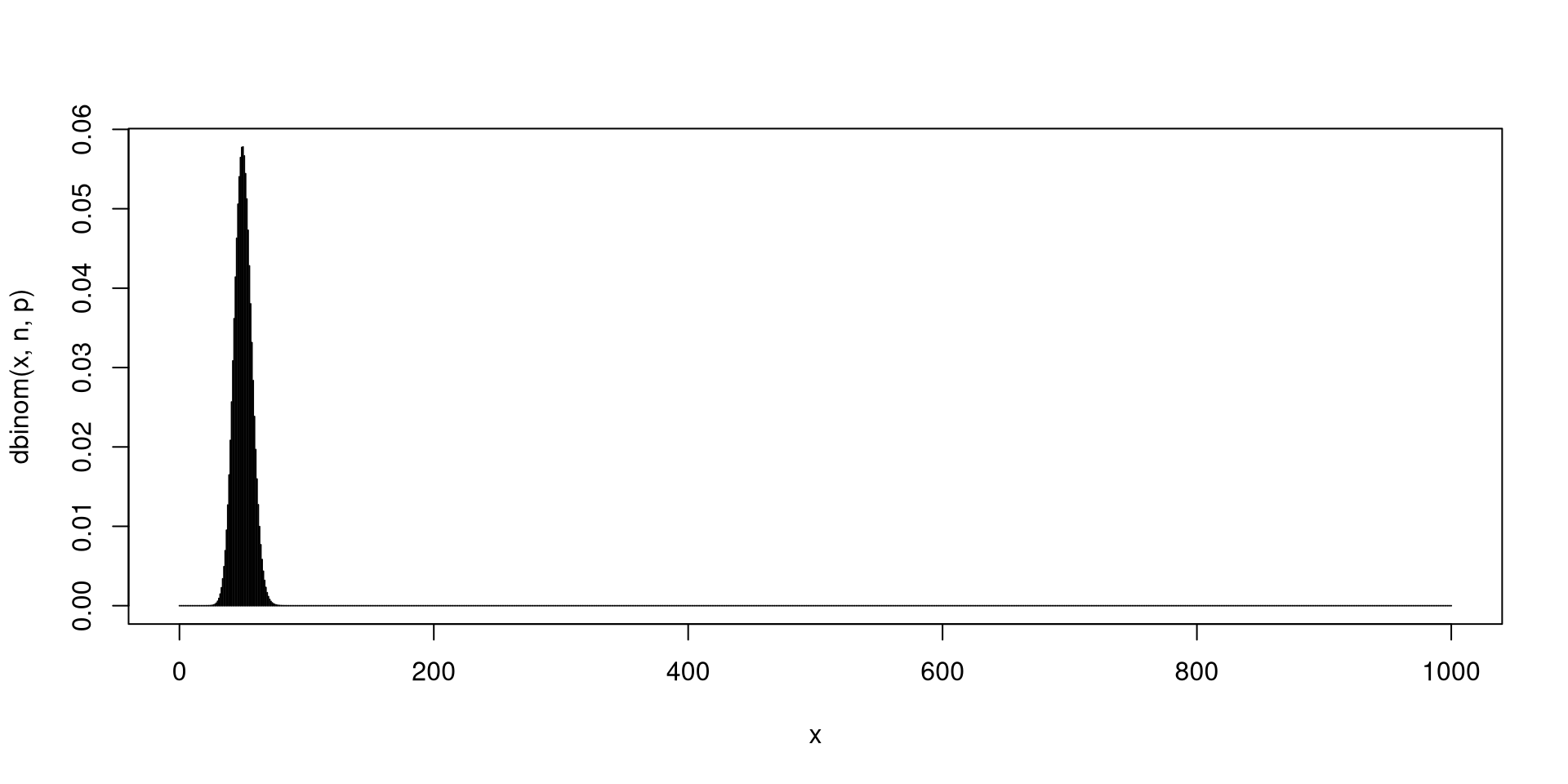
Fix \(n\) as a positive integer and \(0<p<1\). If there are \(n\) independent Bernoulli trials with each trial having the same probability of success \(p\), then the total number of successes \(X\) has a Binomial distribution with parameters \(n\) and \(p\). In short, \(X\sim \mathsf{Bin}\left(n,p\right)\).
You have seen a simulated version of a binomially distributed r.v.’s in the previous slides.
Next, you will plots of the probability distributions for binomial r.v.’s.
By default, the sample() command is used to draw random numbers from the discrete uniform.
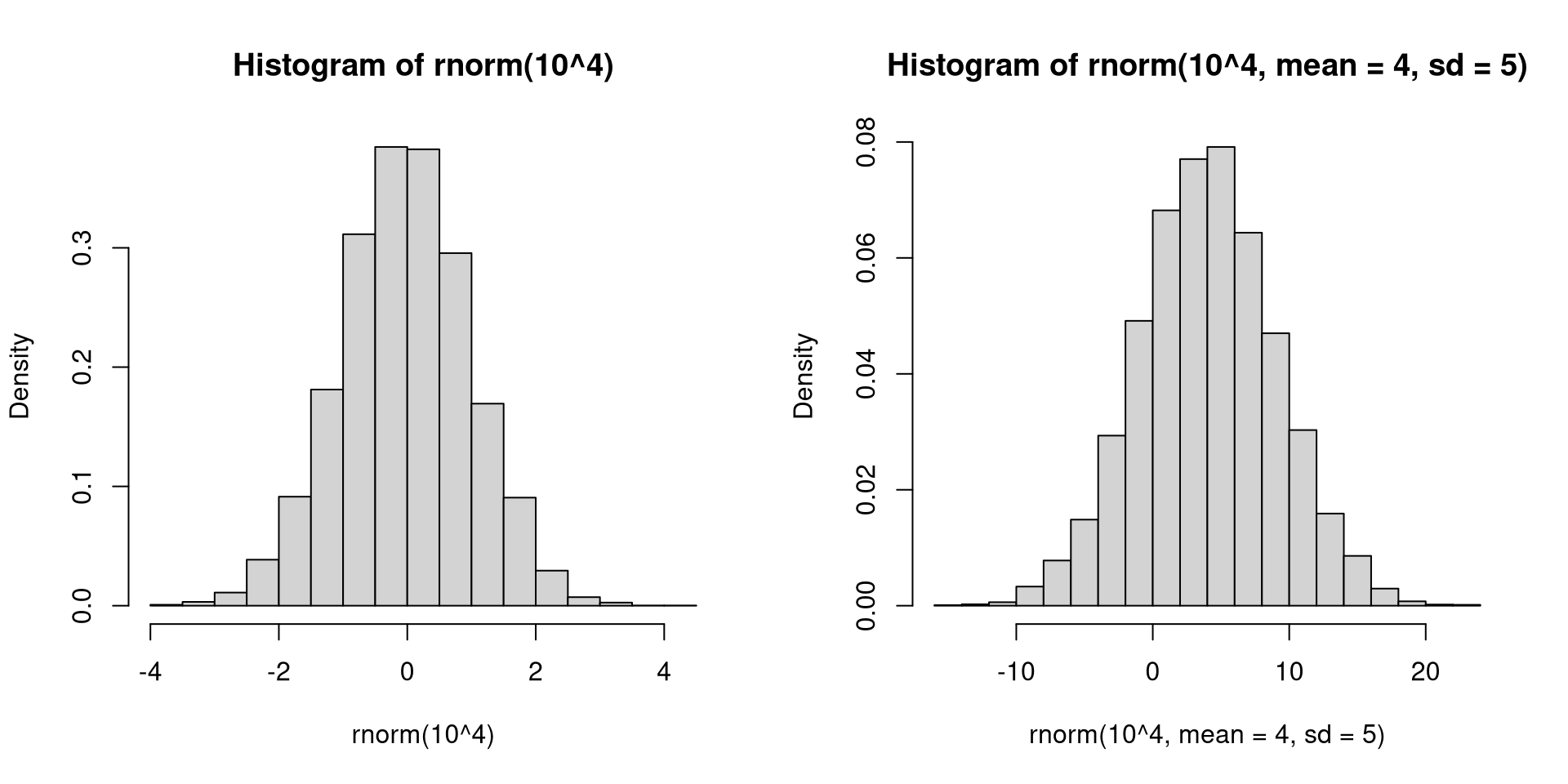
sample() has options to allow for non-fair die rolls if you want.This distribution is denoted by \(N\left(0,1\right)\).
The word “standard” comes from the standardizing idea you have encountered before.
The probability density is given by \[\phi\left(x\right) = \frac{1}{\sqrt{2\pi}} \exp \left(-\frac{1}{2}x^2\right).\]
If \(X\sim N(0,1)\), then \(\mathbb{E}\left(X\right)=0\) and \(\mathsf{Var}\left(X\right)=1\).
The area between -1 to 1 is roughly 68%. The area between -2 to 2 is roughly 95%. The area between -3 to 3 is roughly 99.7%.
Typically, probabilities from the standard normal are obtained from a table or from software.
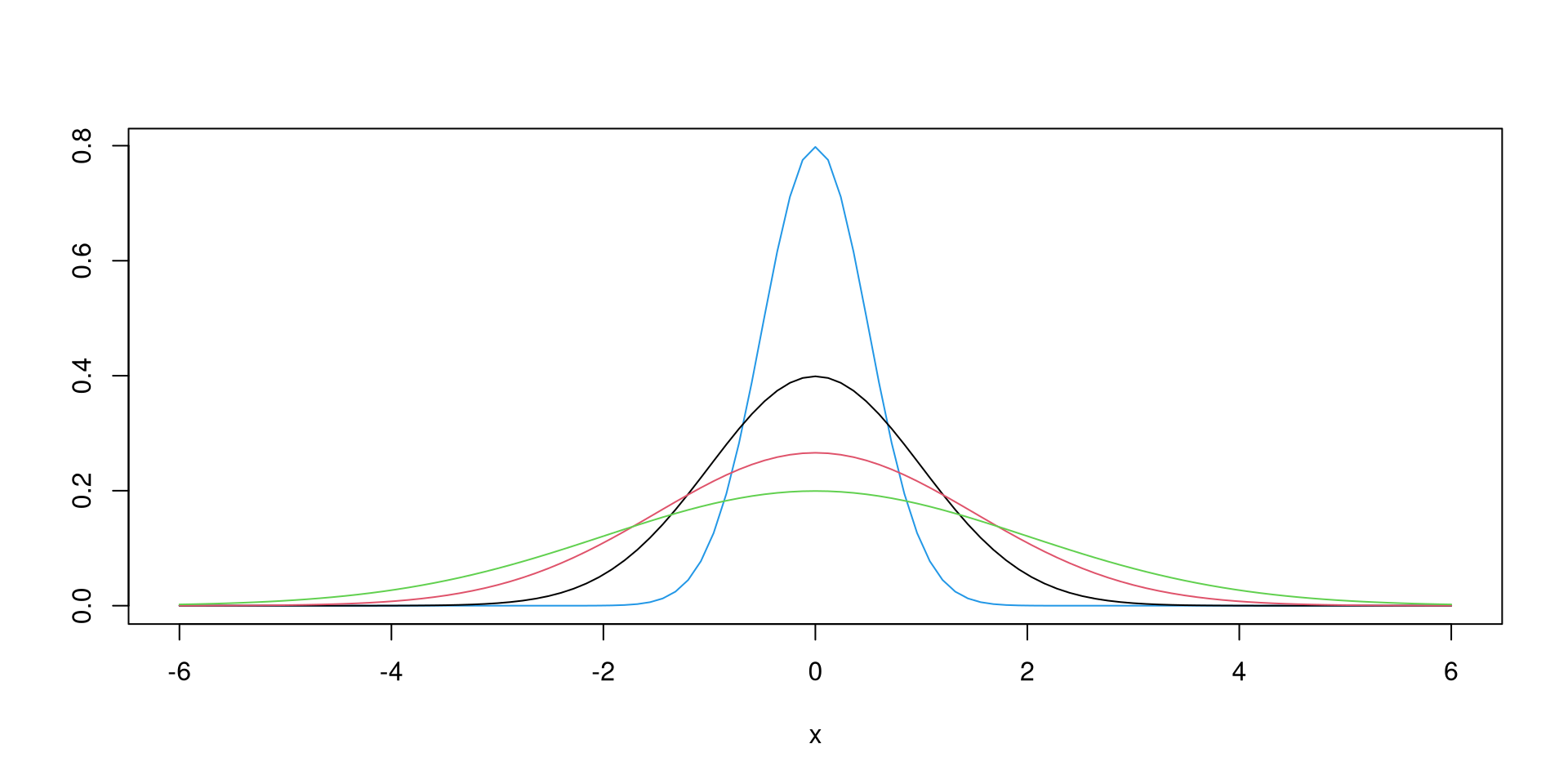
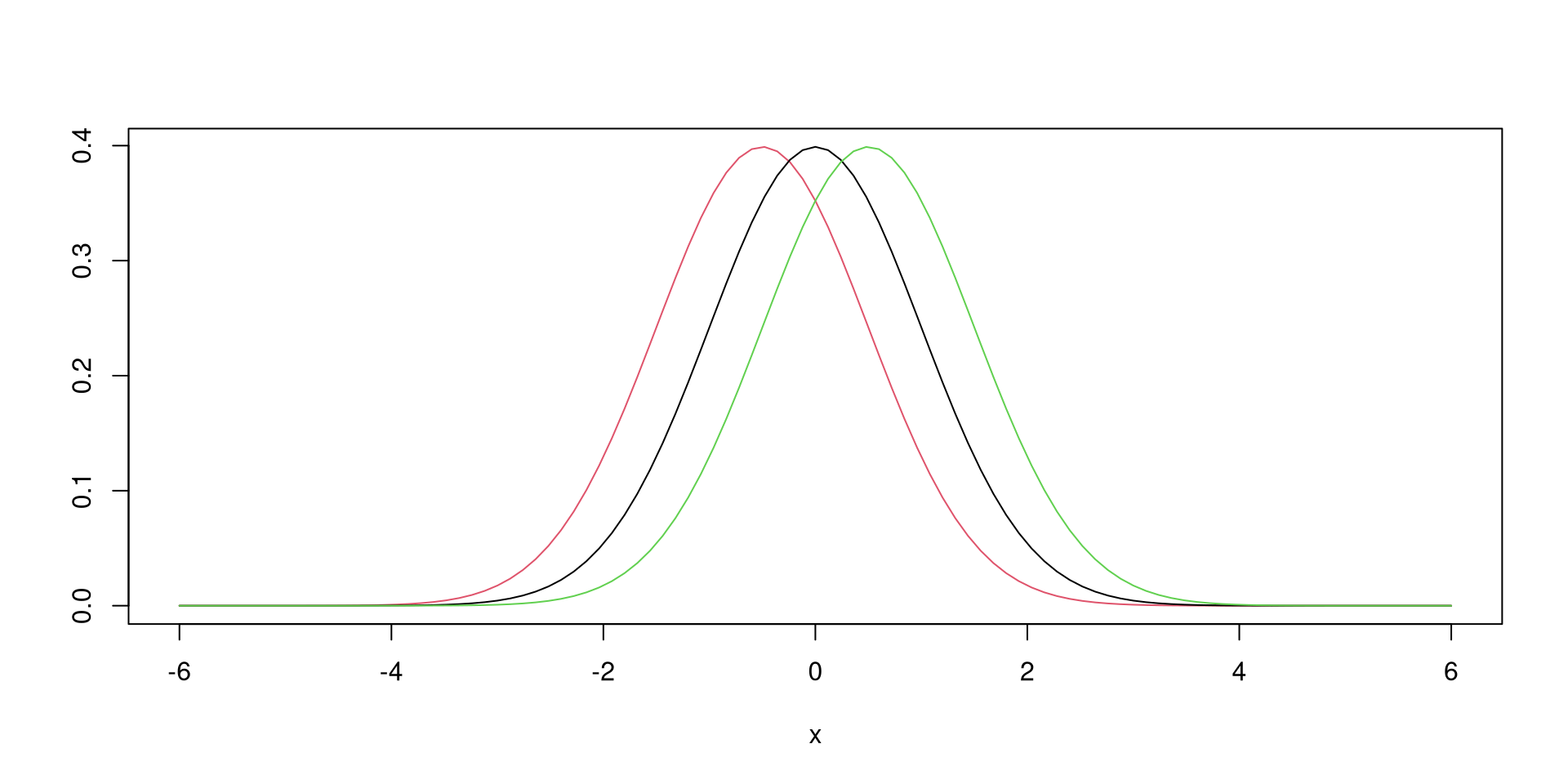
Set \(\mu=0\) and allow \(\sigma\) to vary (0.5 in blue, 1 in black, 1.5 in red, 2 in green).
curve(dnorm(x, mean = 0, sd = 0.5), from = -6, to = 6, col = 4, ylab = "")
curve(dnorm(x, mean = 0, sd = 1), from=-6, to=6, add = TRUE, ylab = "")
curve(dnorm(x, mean = 0, sd = 1.5), from=-6, to = 6, add = TRUE, col=2, ylab = "")
curve(dnorm(x, mean = 0, sd = 2), from=-6, to = 6, add = TRUE, col=3, ylab = "")Set \(\sigma=1\) and allow \(\mu\) to vary (-0.5 in red, 0 in black, 0.5 in green).
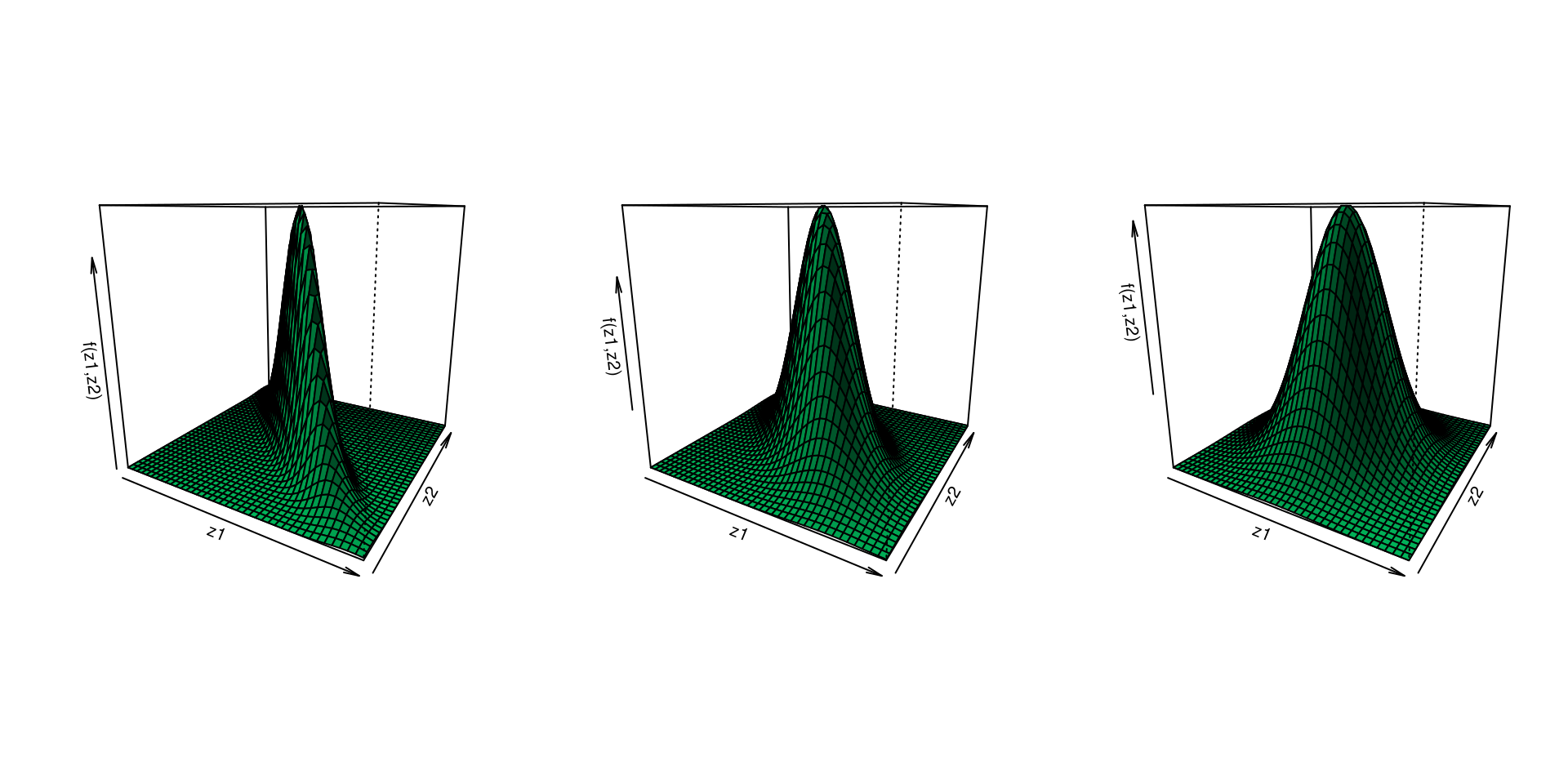
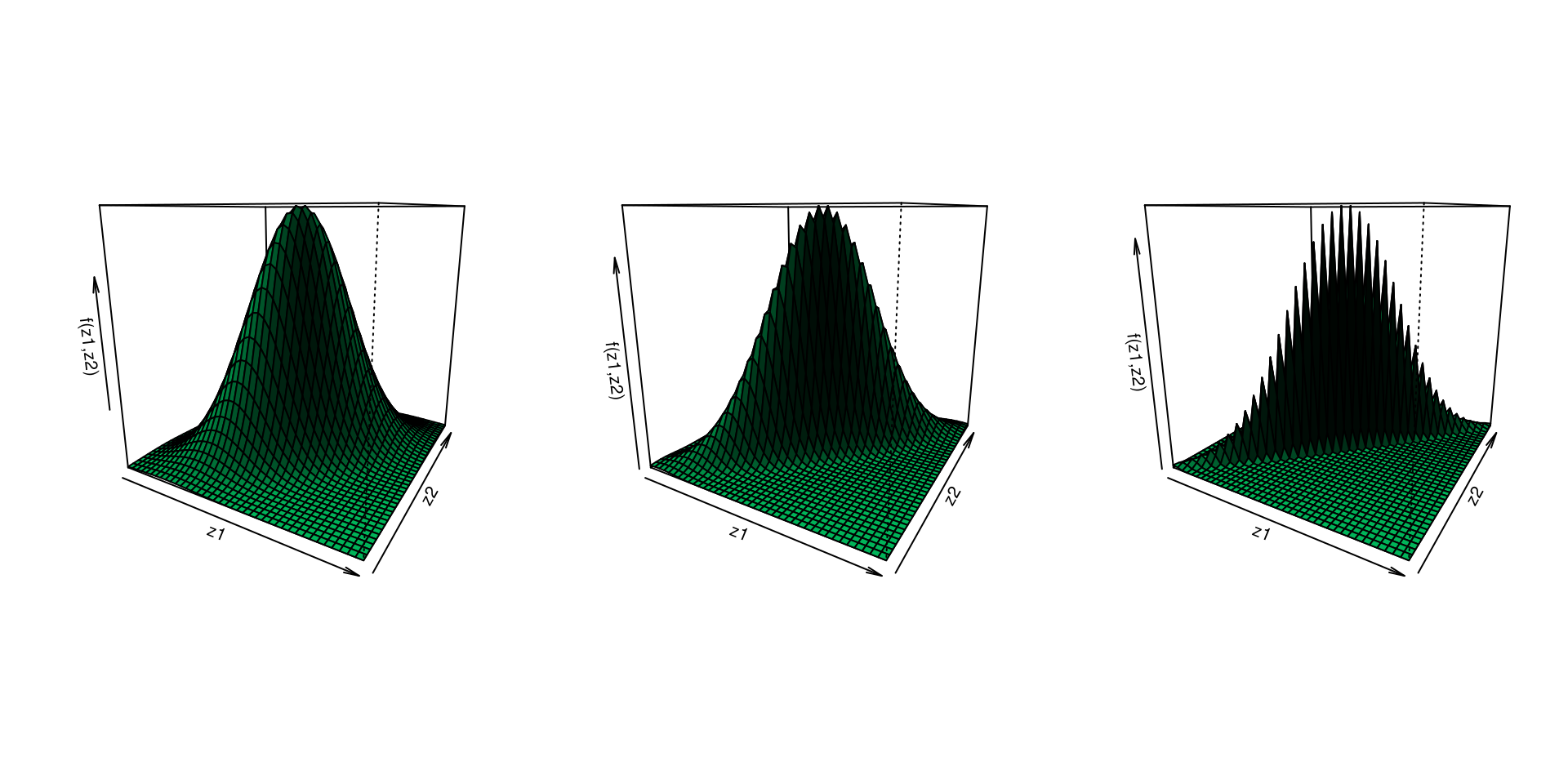
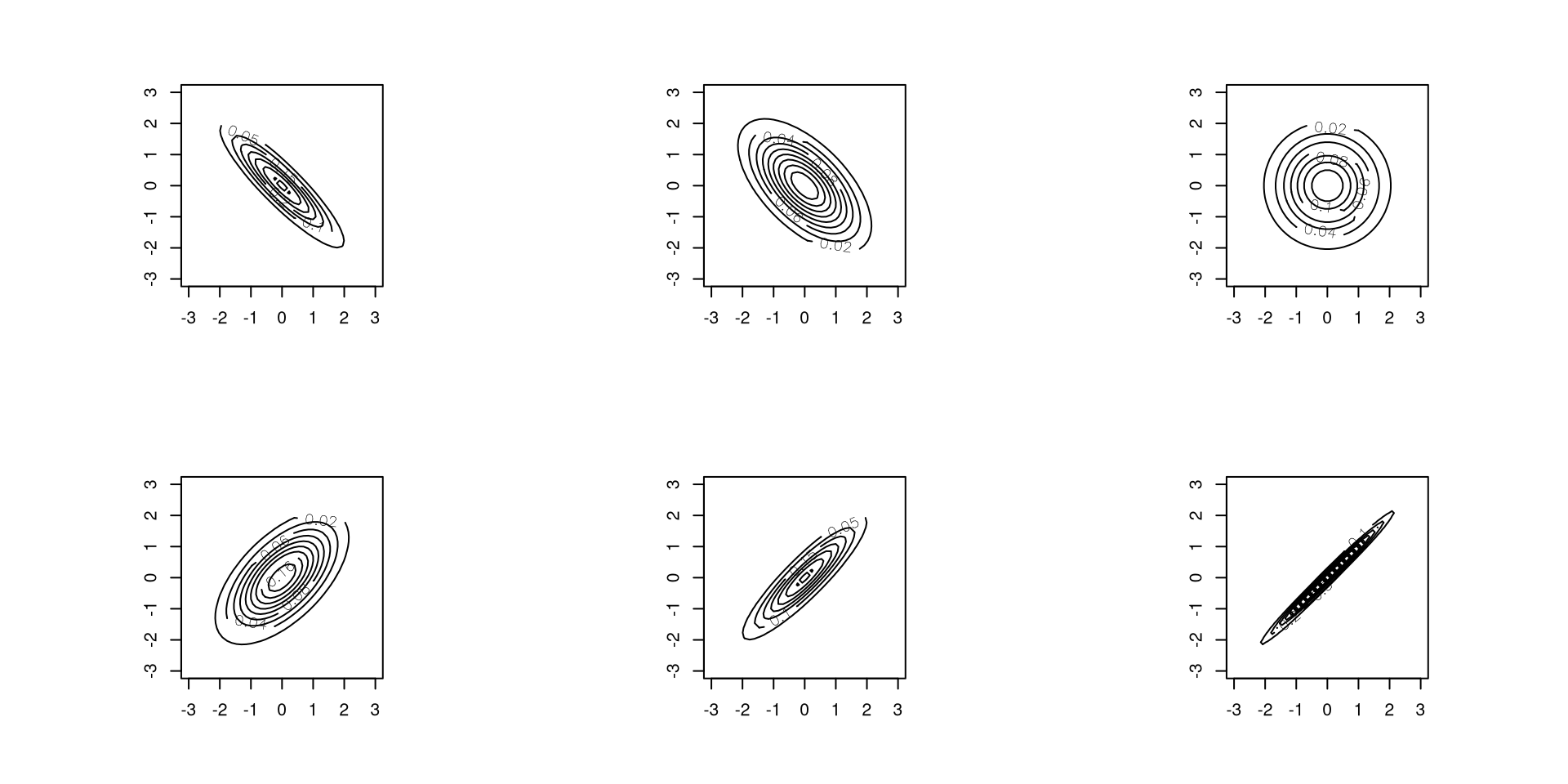
We can extend the standard normal distribution to two dimensions.
We have to think about the more interesting case where two standard normal random variables are not independent of each other.
We will be introducing a parameter \(\rho\) to reflect this dependence.
Let \[Z_1 = U_1,\quad Z_2=\rho U_1+\sqrt{1-\rho^2} U_2\] where \(U_1\sim N\left(0,1\right)\), \(U_2\sim N\left(0,1\right)\) and \(U_1\) is independent of \(U_2\).
It has the following properties: \[\mathbb{E}\left(Z_1\right)=\mathbb{E}\left(Z_2\right)=0, \quad \mathsf{V}\left(Z_1\right)=\mathsf{V}\left(Z_2\right)=1, \quad \mathsf{Cov}\left(Z_1,Z_2\right)=\rho\]
\[f\left(z_1,z_2\right)=\frac{1}{2\pi\sqrt{1-\rho^2}} \exp\left(-\frac{1}{2}\frac{z_1^2+z_2^2-2\rho z_1z_2}{1-\rho^2}\right).\] This density is called the standard bivariate normal distribution with parameter \(\rho\), i.e., \(\left(Z_1,Z_2\right) \sim \mathsf{SBVN}\left(\rho\right)\).
\(\rho \in \{-0.9, -0.6, 0\}\)
\(\rho \in \{0.6, 0.9, 0.99\}\)
We can now extend to bivariate normal distributions with general means and variances.
Let \(X_1=\mu_1+\sigma_1 Z_1\) and \(X_2=\mu_2+\sigma_2 Z_2\).
Observe that \[\mathbb{E}\left(X_1\right)=\mu_1, \quad \mathbb{E}\left(X_2\right)=\mu_2, \quad \mathsf{V}\left(X_1\right)=\sigma^2_1, \quad \mathsf{V}\left(X_2\right)=\sigma^2_2.\]
Further observe that \[\sigma_{12}=\mathsf{Cov}\left(X_1,X_2\right)=\mathsf{Cov}\left(Z_1,Z_2\right)\sigma_1\sigma_2=\rho\sigma_1\sigma_2.\]
\[\overline{X} = \frac{1}{n}\sum_{t=1}^n X_t\]
\[\begin{eqnarray} \mathbb{E}\left(\overline{X}\right) &=& \mu\\ \mathsf{Var}\left(\overline{X}\right) &=& \frac{1}{n}\cdot \sigma^2 \end{eqnarray}\]
nsim <- 10^4
set1 <- replicate(nsim, rbinom(10, 1, 0.05))
set2 <- replicate(nsim, rbinom(40, 1, 0.05))
set3 <- replicate(nsim, rbinom(160, 1, 0.05))
set4 <- replicate(nsim, rbinom(640, 1, 0.05))
props1 <- colMeans(set1); props2 <- colMeans(set2); props3 <- colMeans(set3); props4 <- colMeans(set4)
# spreads from the simulated sampling distribution
c(sd(props1), sd(props2), sd(props3), sd(props4))[1] 0.068702521 0.034576705 0.017085381 0.008545212# average of standard errors computed for each replication
c(mean(apply(set1, 2, sd))/sqrt(10), mean(apply(set2, 2, sd))/sqrt(40), mean(apply(set3, 2, sd))/sqrt(160), mean(apply(set4, 2, sd))/sqrt(640))[1] 0.042617354 0.031201960 0.017014001 0.008585628# formula-based standard error (had we known the unknown variance)
c(sqrt(0.05*0.95/10), sqrt(0.05*0.95/40), sqrt(0.05*0.95/160), sqrt(0.05*0.95/640))[1] 0.06892024 0.03446012 0.01723006 0.00861503The last set of standard errors exploits knowledge about the unknown DGP and serves as a benchmark. We typically do not know this in practice.
When \(n\) is small, the standard errors we can compute in practice may not perform very well. But it gets better with large \(n\).
IID random variables is really the same as obtaining a random sample.
The sample mean \(\overline{X}\) will be different every time you gather a random sample from the same population.
It is possible to write down all possible values of \(\overline{X}\), but we do not know which will be realized for a particular random sample.
This means that \(\overline{X}\) is also a random variable which has a probability distribution (which some people call the sampling distribution of \(\overline{X}\)).
In particular, the expectation of \(\overline{X}\) is actually the population average.
Notice that the population size does not matter when deciding how to reduce the variance of \(\overline{X}\).
Note that \[\mathsf{Var}\left(\overline{X}\right)=\mathbb{E}\left[\left(\overline{X}-\mathbb{E}\left(\overline{X}\right)\right)^2\right]=\mathbb{E}\left[\left(\overline{X}-\mu\right)^2\right]\]
Observe that \(\mathsf{Var}\left(\overline{X}\right)\) tends to zero with increasing \(n\).
\(\sqrt{\mathsf{Var}\left(\overline{X}\right)}\) is the standard deviation of the sampling distribution of \(\overline{X}\). We abbreviate this as the standard error of \(\overline{X}\).
Notice that the standard error of \(\overline{X}\) declines at the \(\sqrt{n}\) rate.
This means that reducing this standard error in half require a four-fold increase in the number of observations.
Another convergence concept stems from the behavior of the probability of the event that \[|Z_n-Z|\geq \epsilon\] as \(n\to\infty\), for any pre-specified \(\epsilon>0\).
Let \(Z_1,Z_2,\ldots\) be a sequence of random variables. This sequence is said to converge in probability to a random variable \(Z\), denoted by \(Z_n \overset{p}{\to} Z\), if for any \(\epsilon>0\), \[\lim_{n\to\infty}\mathbb{P}\left(|Z_n-Z|\geq \epsilon\right)\to 0\]
Sometimes, \(Z_n \overset{p}{\to} Z\) can be written as \(\underset{n\to\infty}{\mathrm{plim}} Z_n = Z\).
We will not prove that \(\overline{X} \overset{p}{\to} \mu\), but demonstrate it using a separate simulation.
The result is one of the most celebrated theorems in probability, called the law of large numbers for sequences of IID random variables.
We also have if \(g\) is a continuous function and \(Z_n \overset{p}{\to} Z\), then \(g\left(Z_n\right) \overset{p}{\to} g\left(Z\right)\).
Suppose \(\beta_1\) is the population parameter of interest.
Consider the procedure behind lm() to produce regression coefficients:
\[\widehat{\beta}_1=\frac{\displaystyle\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)\left(Y_{t}-\overline{Y}\right)}{\displaystyle\sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)^2} \]
\[\begin{eqnarray} \mathbb{E}\left(\widehat{\beta}_1\right) &=& \beta_1 \\ \mathsf{Var}\left(\widehat{\beta}_1\right) &=& \frac{\sigma^2}{\displaystyle \sum_{t=1}^n \left(X_{1t}-\overline{X}_1\right)^2} \end{eqnarray}\]
lm() actually uses the formula you have just seen for \(\mathsf{Var}\left(\widehat{\beta}_1\right)\) by default.lm().# Number of observations
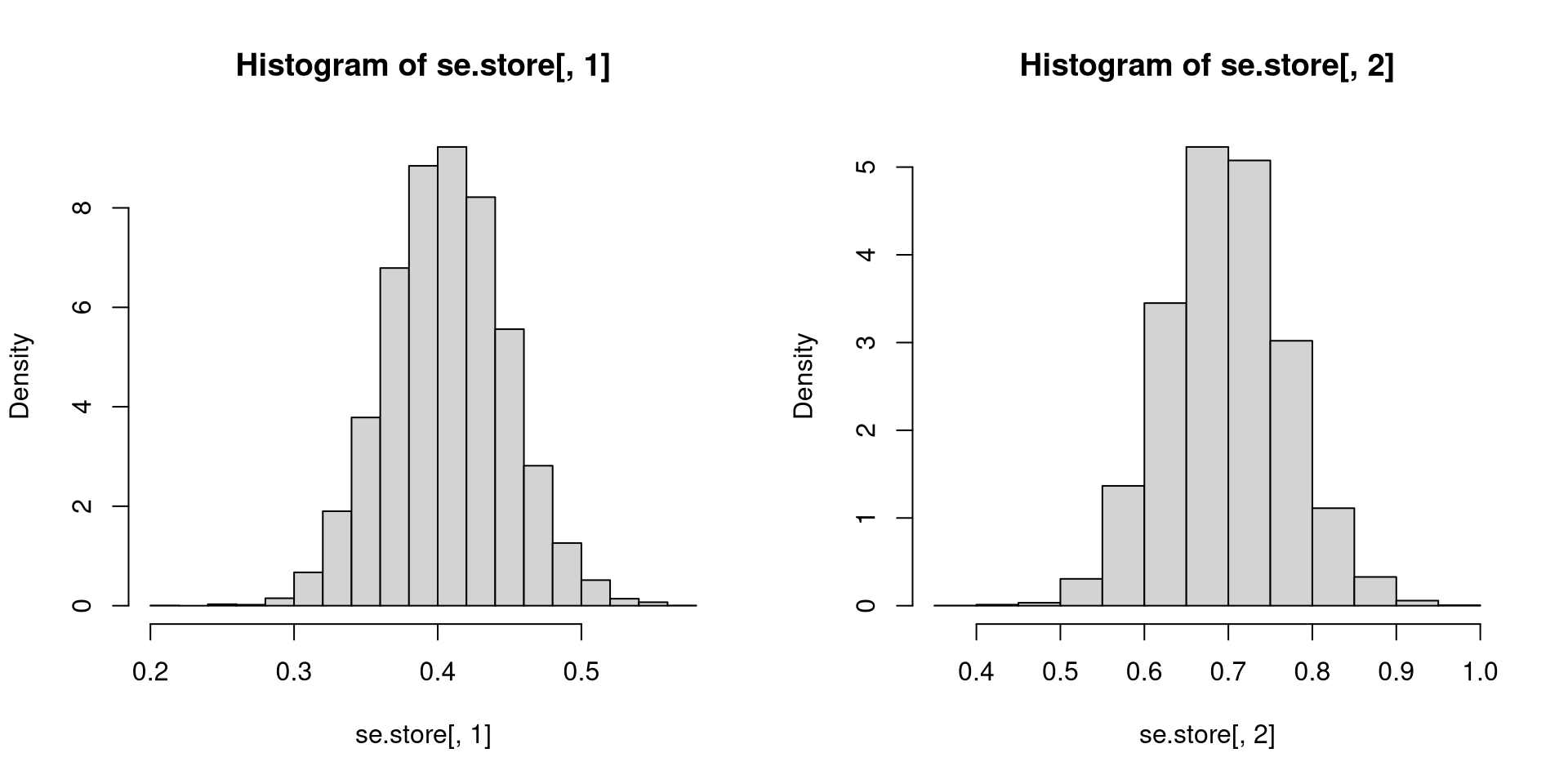
n <- 50
# How many times to loop
reps <- 10^4
# Storage for OLS results (2 entries per replication)
beta.store <- matrix(NA, nrow=reps, ncol=2)
se.store <- matrix(NA, nrow=reps, ncol=2)
# Generate X, fixed in repeated samples
X.t <- rbinom(n, 1, 0.3)
# Monte Carlo loop
for (i in 1:reps)
{
eps.t <- (rnorm(n, 0, 4))*(X.t == 1)+(rnorm(n, 0, 1))*(X.t == 0)
Y.t <- 3 + 2*X.t + eps.t # Generate Y
temp <- lm(Y.t ~ X.t)
beta.store[i,] <- coef(temp)
se.store[i,] <- sqrt(diag(vcov(temp)))
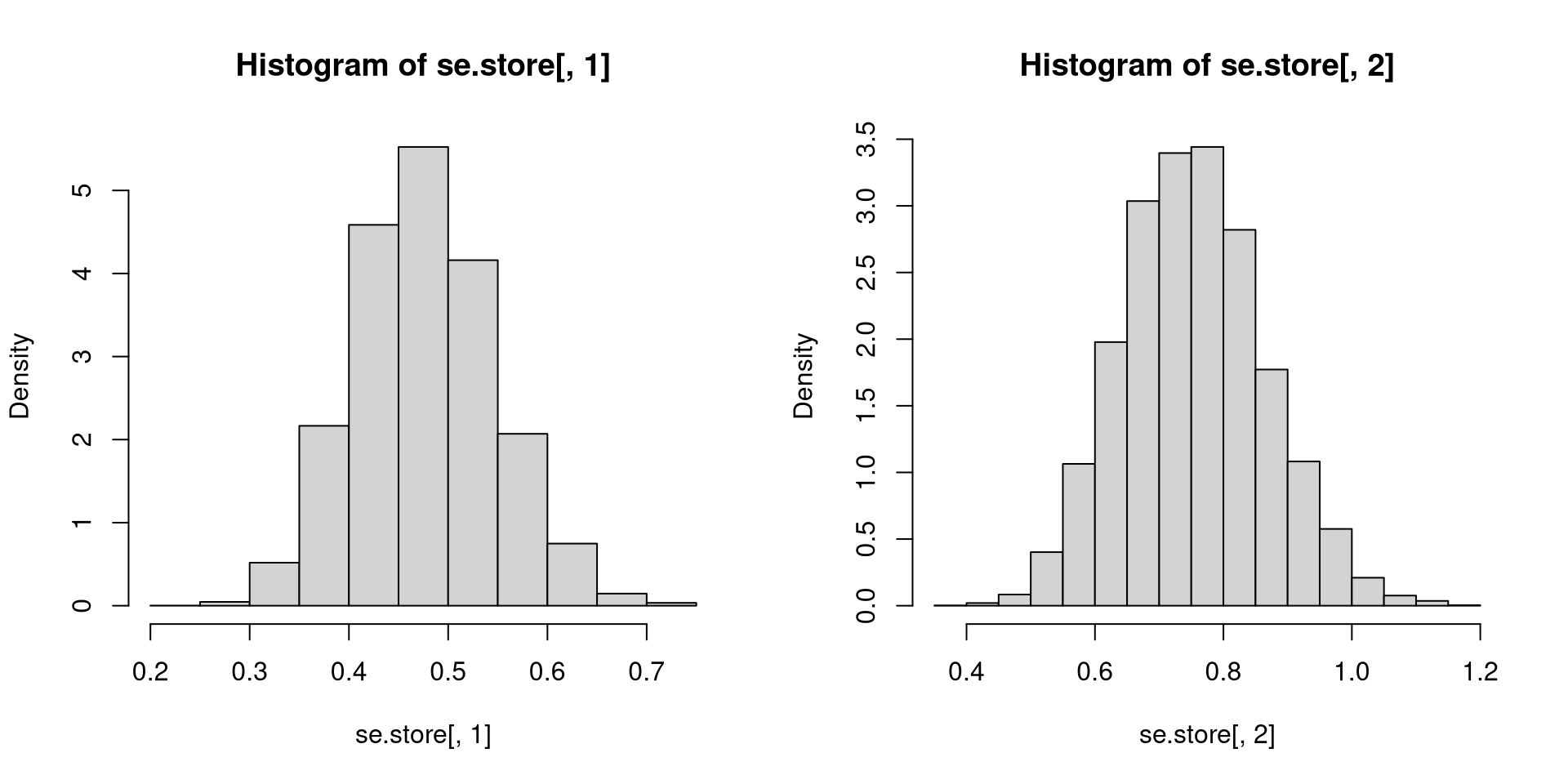
}[1] 0.1808311 0.9136103[1] 0.4765645 0.7535147[1] 0.6770032lm() has implementable formulas for the standard errors.# Number of observations
n <- 200
# How many times to loop
reps <- 10^4
# Storage for OLS results (2 entries per replication)
beta.store <- matrix(NA, nrow=reps, ncol=2)
se.store <- matrix(NA, nrow=reps, ncol=2)
# Generate X, fixed in repeated samples
X.t <- rbinom(n, 1, 0.3)
# Monte Carlo loop
for (i in 1:reps)
{
eps.t <- (rnorm(n, 0, 4))*(X.t == 1)+(rnorm(n, 0, 1))*(X.t == 0)
Y.t <- 3 + 2*X.t + eps.t # Generate Y
temp <- lm(Y.t ~ X.t)
beta.store[i,] <- coef(temp)
se.store[i,] <- sqrt(diag(vcov(temp)))
}[1] 0.08585161 0.50083412[1] 0.2095471 0.3647747[1] 0.3526728# Number of observations
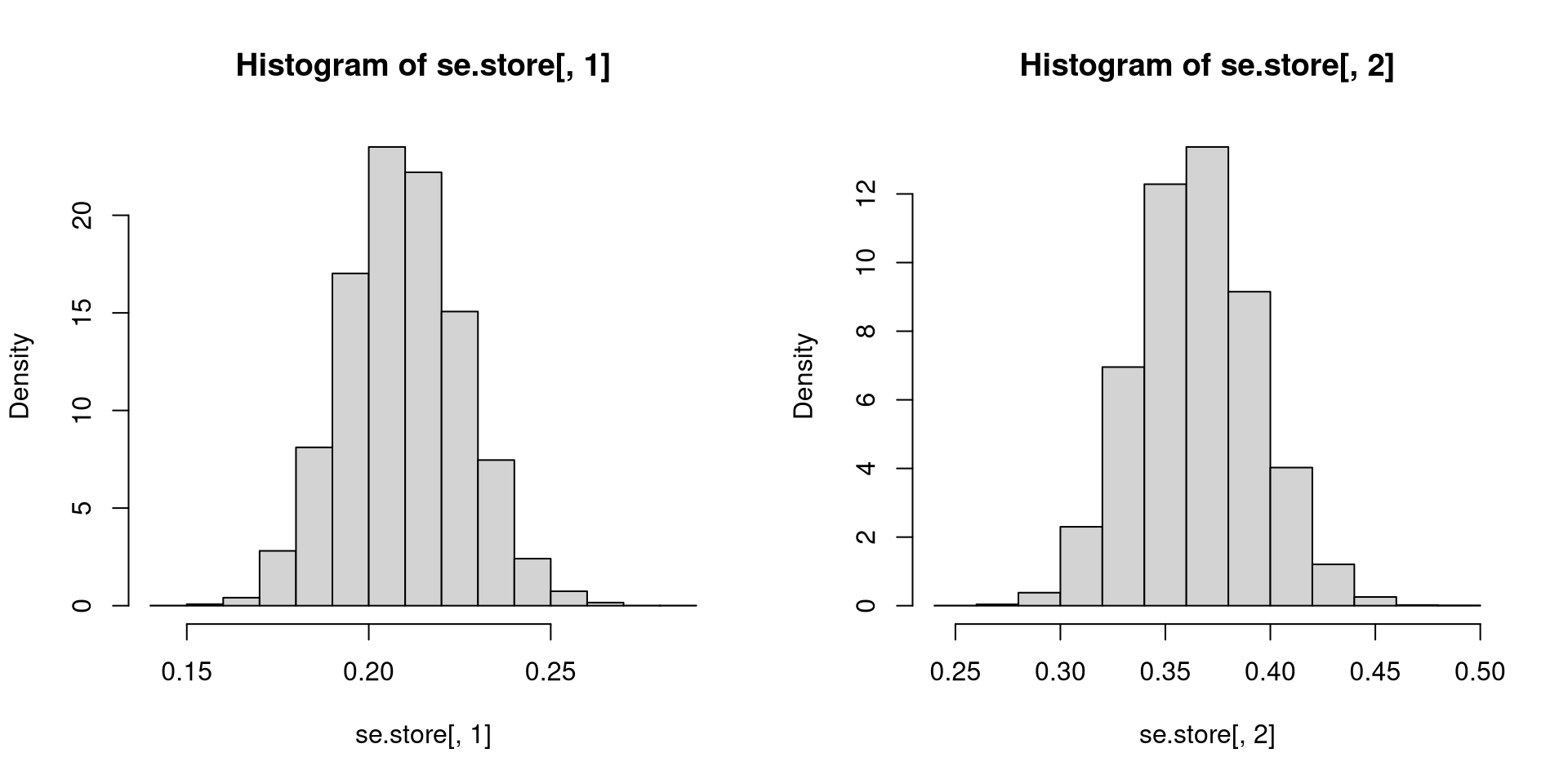
n <- 50
# How many times to loop
reps <- 10^4
# Storage for OLS results (2 entries per replication)
beta.store <- matrix(NA, nrow=reps, ncol=2)
se.store <- matrix(NA, nrow=reps, ncol=2)
# Generate X, fixed in repeated samples
X.t <- rbinom(n, 1, 0.3)
# Monte Carlo loop
for (i in 1:reps)
{
eps.t <- rnorm(n, 0, sqrt(5.5))
Y.t <- 3 + 2*X.t + eps.t # Generate Y
temp <- lm(Y.t ~ X.t)
beta.store[i,] <- coef(temp)
se.store[i,] <- sqrt(diag(vcov(temp)))
}Suppose there is a finite population of size \(N\) and each member of this population has some characteristic of interest.
Let \(\Omega=\{\omega_1,\ldots,\omega_N\}\) be the sample space representing the identity of the members of the population.
Let \(X\left(\omega_k\right)\) be the corresponding characteristic of \(\omega_k\).
Define the population average for that characteristic to be \[\mu=\frac{1}{N}\sum_{k=1}^N X\left(\omega_k\right)\]
Surveys rely on sampling a small fraction of this population. Let \(n\) be the sample size.
Define a random variable \(\alpha_t\left(\omega\right)\) where \(\omega\in\Omega\), which is equal to any of \(\omega_1,\ldots,\omega_N\), depending on which was sampled on the \(t\)th draw.
Define the sample mean to be \[\overline{X} = \frac{1}{n}\sum_{t=1}^n X\left(\alpha_t\right) \]
What do we learn from the survey? There are two cases to consider:
Depending on which units were sampled, \(\overline{X}\) will be different every time.
We may know what the possible values of \(\overline{X}\), but do not know which will be realized for a particular survey.
This means that \(\overline{X}\) is also a random variable which has a probability distribution (which some people call the sampling distribution of \(\overline{X}\)).
It will have moments, provided they exist.
In particular, the expectation of \(\overline{X}\) is actually the population average.
Furthermore, the findings about the variance of \(\overline{X}\) depends on the case:
It is important not to lose sight of what \(\mathsf{Var}\left(\overline{X}\right)\) really means.
One of the four words in the sentence “I SEE THE MOUSE” will be selected at random. This means that each of these words are equally likely to be chosen.
The task is to predict the number of letters in the selected word.
Your error would be the number of letters minus the predicted number of letters.
The square of your error will be your loss.
Because you do not know for sure which word will be chosen, you have to allow for contingencies.
Therefore, losses depend on which word was chosen.
What would be your prediction rule in order to make your expected loss as small as possible?
How much would be the smallest expected loss?
There is some random variable \(Y\) whose value you want to predict.
You make a prediction (a real number \(\beta_0\)).
You make an error \(Y-\beta_0\), but this error is a random variable having a distribution.
Next, you have have some criterion to assess whether your prediction is “good”.
You need a loss function. There are many choices, which are not limited to: \[L\left(z\right)=z^{2},L\left(z\right)=\left|z\right|,L\left(z\right)=\begin{cases} \left(1-\alpha\right)\left|z\right| & \mathsf{if}\ z\leq0\\ \alpha\left|z\right| & \mathsf{if}\ z\geq0 \end{cases}\]
But losses will have a distribution too.
We can look at expected losses. This may seem arbitrary but many prediction and forecasting contexts use expected losses.
Consider \(L\left(z\right)=z^{2}\) and form an expected squared loss \(\mathbb{E}\left[\left(Y-\beta_0\right)^{2}\right]\).
This expected loss is sometimes called mean squared error (MSE).
You can show that \(\mathbb{E}\left(Y\right)\) is the unique solution to the following optimization problem: \[\min_{\beta_0}\mathbb{E}\left[\left(Y-\beta_0\right)^{2}\right]\]
\(\mathbb{E}\left(Y\right)\) is given another interpretation as the optimal predictor.
We also have a neat connection with the definition of the variance:
What happens if we have additional information which we may use for prediction?
Return to our toy example.
Let us now predict the number of letters \(Y\) in the selected word, given that you know the number of E’s in the word, denote this as \(X_1\).
Clearly, knowing the value of \(X_1\) for the selected word could help.
How do we incorporate this additional information for prediction?
As a result, we have \[\beta_{0}^{*} = \mathbb{E}\left(Y\right)-\beta_{1}^{*}\mathbb{E}\left(X_{1}\right),\qquad\beta_{1}^{*}=\dfrac{\mathbb{E}\left(X_1Y\right)-\mathbb{E}\left(Y\right)\mathbb{E}\left(X_1\right)}{\mathbb{E}\left(X_1^2\right)-\mathbb{E}\left(X_1\right)^2}.\]
In the end, we have \[\beta_{0}^{*} = \mathbb{E}\left(Y\right)-\beta_{1}^{*}\mathbb{E}\left(X_{1}\right),\qquad\beta_{1}^{*}=\dfrac{\mathsf{Cov}\left(X_{1},Y\right)}{\mathsf{Var}\left(X_{1}\right)}.\]
Take note of how we computed linear regression in lm(). Do you find some similarities?
In fact, the similarities are so suggestive that it can be shown that under an IID sample \(\{\left(X_{1t} , Y_t\right)\}_{t=1}^n\) from the joint distribution of \((X,Y)\), we have \[\widehat{\beta}_1 \overset{p}{\to} \beta^*_1,\ \ \ \widehat{\beta}_0 \overset{p}{\to} \beta^*_0\]
Recall that the task is to predict the number of letters in the selected word. Each word is equally likely to be chosen.
Let \(Y\) be the number of letters in the selected word.
The optimal predictor under an MSE criterion for \(Y\) is \(\mathbb{E}\left(Y\right)\). Here, we have \(\mathbb{E}\left(Y\right)=3\).
If we have information on the number of E’s in the word, what will be your prediction? Let \(X_1\) denote the number of E’s in the word.
We have found a formula for the optimal linear predictor which is \(\beta_0^* +\beta_1^*X_1\), where \(\beta_0^*\) and \(\beta_1^*\) have forms we have derived earlier.
You can show that the optimal linear predictor is \(2+X_1\). Notice that this optimal linear predictor uses information about the number of E’s in the word to make predictions.
Contrast this to the case where we did not know the number of E’s in the word.
We can always write \[Y_t=\beta_0^*+\beta_1^* X_{1t} + \varepsilon_t\] such that \(\mathbb{E}\left(\varepsilon_t\right)=0\) and \(\mathbb{E}\left(X_{1t}\varepsilon_t\right)=0\).
\(\mathbb{E}\left(\varepsilon_t\right)=0\) and \(\mathbb{E}\left(X_{1t}\varepsilon_t\right)=0\) together imply that \(\mathsf{Cov}\left(X_{1t},\varepsilon_t\right)=0\).
Contrast this to the first version of the linear regression model you have seen earlier.
Usually, introductory textbooks will write down an equation like \[Y_t=\beta_0+\beta_1 X_{1t} + \varepsilon_t\] and then make assumptions about \(\varepsilon_t\). The task is to learn \(\beta_0\) and \(\beta_1\).
If you assume that \(\varepsilon_t\) satisfies \(\mathbb{E}\left(\varepsilon_t\right)=0\) and \(\mathbb{E}\left(X_{1t}\varepsilon_t\right)=0\) then, \(\beta_0\) and \(\beta_1\) automatically coincides with the coefficients of the optimal linear predictor.
The approach presented in the slides gives you a clearer motivation as to why we could interpret coefficients produced by lm() as predicted differences.
Actually in introductory textbooks, they impose a stronger assumption on \(\varepsilon_t\). They would say that \(\varepsilon_t\) is mean-independent of \(X_{1t}\).
This motivates us to look further into this idea of mean independence.
Return to I SEE THE MOUSE. The next task is to predict the number of letters in the selected word if you have information about the number of E’s in the word (call this \(X_1\)).
In “I SEE THE MOUSE”, knowing the event that the selected word has 1 E, reduces the sample space of words from \[\{\mathrm{I}, \mathrm{SEE}, \mathrm{THE}, \mathrm{MOUSE}\}\] to \[\{\mathrm{THE}, \mathrm{MOUSE}\}\]
As a result, your prediction of the number of letters will definitely change.
We now define a concept called the expectation of a random variable conditional on an event: Let \(Y\) be a random variable and let \(A\) be an event. Then, \[\mathbb{E}\left(Y|A\right)=\frac{\mathbb{E}\left(YI\left(A\right)\right)}{\mathbb{E}\left(I\left(A\right)\right)}=\frac{\mathbb{E}\left(YI\left(A\right)\right)}{\mathbb{P}\left(A\right)}\]
Take note of the similarity of the definition to how you would compute a subgroup average with real data.
Of course, \(\mathbb{P}\left(A\right)>0\) for this \(\mathbb{E}\left(Y|A\right)\) to be well-defined.
If \(\mathbb{P}\left(A\right)>0\), then \(\mathbb{E}\left(\cdot|A\right)\) has to satisfy the axioms of the expectation operator.
If \(\Omega\) can be decomposed into disjoint events \(\left\{A_k\right\}\), then \[\mathbb{E}\left(Y\right) = \sum_k \mathbb{P}\left(A_k\right)\mathbb{E}\left(Y|A_k\right)\]
Let \(X\) be another random variable. We can also condition on the possible values of \(X\). For example, let \(x\) be some specific value that \(X\) could take. The event is then \(X=x\), which is shorthand for \[\{\omega\in\Omega: X\left(\omega\right)=x\}\]
\(\mathbb{E}\left(Y|X=x\right)\) can be directly obtained as a result. This is just a constant.
But the values of \(x\) could vary. In this sense, \(\mathbb{E}\left(Y|X=x\right)\) may also be thought of as a function of \(x\).
Another layer on top of this is that \(X\) is a random variable. Although it is possible to know the alternative values of \(X\), we do not know which will be realized.
That is why we can also think of \(\mathbb{E}\left(Y|X\right)\) as a random variable which has a probability distribution.
A technical problem we face (which affects practice) is that sometimes \(X\) is a continuous random variable. Therefore, \(\mathbb{P}\left(X=x\right)=0\).
But an alternative approach is to define \(\mathbb{E}\left(Y|X\right)\) as a scalar function of \(X\) such that \[\mathbb{E}\left[\left(Y-\mathbb{E}\left(Y|X\right)\right)H\left(X\right)\right]=0\] for any scalar-valued function \(H\left(X\right)\).
Note the similarity of the condition above to the conditions for linear prediction: \[\mathbb{E}\left(Y-\beta_{0}^{*}-\beta_{1}^{*}X\right) = 0, \ \ \mathbb{E}\left[X\left(Y-\beta_{0}^{*}-\beta_{1}^{*}X\right)\right] = 0\]
The conditional expectation and the best linear predictor differ with respect to the class of functions \(H\left(X\right)\).
For the best linear prediction, there are only two functions \(H\left(X\right)=1\) and \(H\left(X\right)=X\) involved (at least in this context of scalar \(Y\) and scalar \(X\)).
This tells us that conditional expectations and best linear predictors are not necessarily the same!
What are the advantages of this alternative approach when thinking of conditional expectations?
If \(X\) and \(Y\) are independent and \(G\) is any function depending on \(Y\) alone, then \(\mathbb{E}\left(G\left(Y\right)|X\right)= \mathbb{E}\left(G\left(Y\right)\right)\).
For any function \(G\) depending on \(X\) alone, \(\mathbb{E}\left(G\left(X\right)\cdot Y|X\right)=G\left(X\right)\cdot \mathbb{E}\left(Y|X\right)\).
Linearity: \(\mathbb{E}\left(Y_1+Y_2|X\right)= \mathbb{E}\left(Y_1|X\right) + \mathbb{E}\left(Y_2|X\right)\).
For any r.v.’s \(X\), \(Y\), and \(Z\), \(\mathbb{E}\left[\mathbb{E}\left(Y|X,Z\right)|Z\right]= \mathbb{E}\left(Y|Z\right)\).
The law of iterated expectations is given by \[\mathbb{E}\left[G\left(X,Y\right)\right]=\mathbb{E}\left[\mathbb{E}\left[G\left(X,Y\right)|X\right]\right].\]
Take note of which distributions are being used to calculate the corresponding expectations.
A more commonly seen version is \[\mathbb{E}\left[Y\right]=\mathbb{E}\left[\mathbb{E}\left(Y|X\right)\right].\]
The law of total variance is given by \[\mathsf{Var}\left(Y\right)=\mathbb{E}\left[\mathsf{Var}\left(Y|X\right)\right]+\mathsf{Var}\left[\mathbb{E}\left(Y|X\right)\right].\]
\(\mathbb{E}\left[\mathsf{Var}\left(Y|X\right)\right]\) is called within-group variation or unexplained variation while \(\mathsf{Var}\left(\mathbb{E}\left(Y|X\right)\right)\) is called between-group variation or explained variation.
Let us revisit I SEE THE MOUSE.
Let us revisit the design in Exercise Set 03. Both the CEF and BLP are given by \(3+2X_1\).
(A version of Aronow and Miller (2009)) Let \(Y=X_1^2+W\) where \(W\) and \(X\) are independent.
Changing the distribution of \(X_1\) also changes the best linear predictor. In this example, the CEF is the same regardless of the distribution of \(X_1\).
It is not worth the trouble to write down the conditions where the two could be equal.
Two popular examples:
The latter is probably most practically relevant. The latter is sometimes called a saturated model.
Estimation and inference could be tricky for the CEF.
What you are going to see is a very naive form of nonparametric regression. If you want to learn more, I would suggest Henderson and Parmeter (2015).
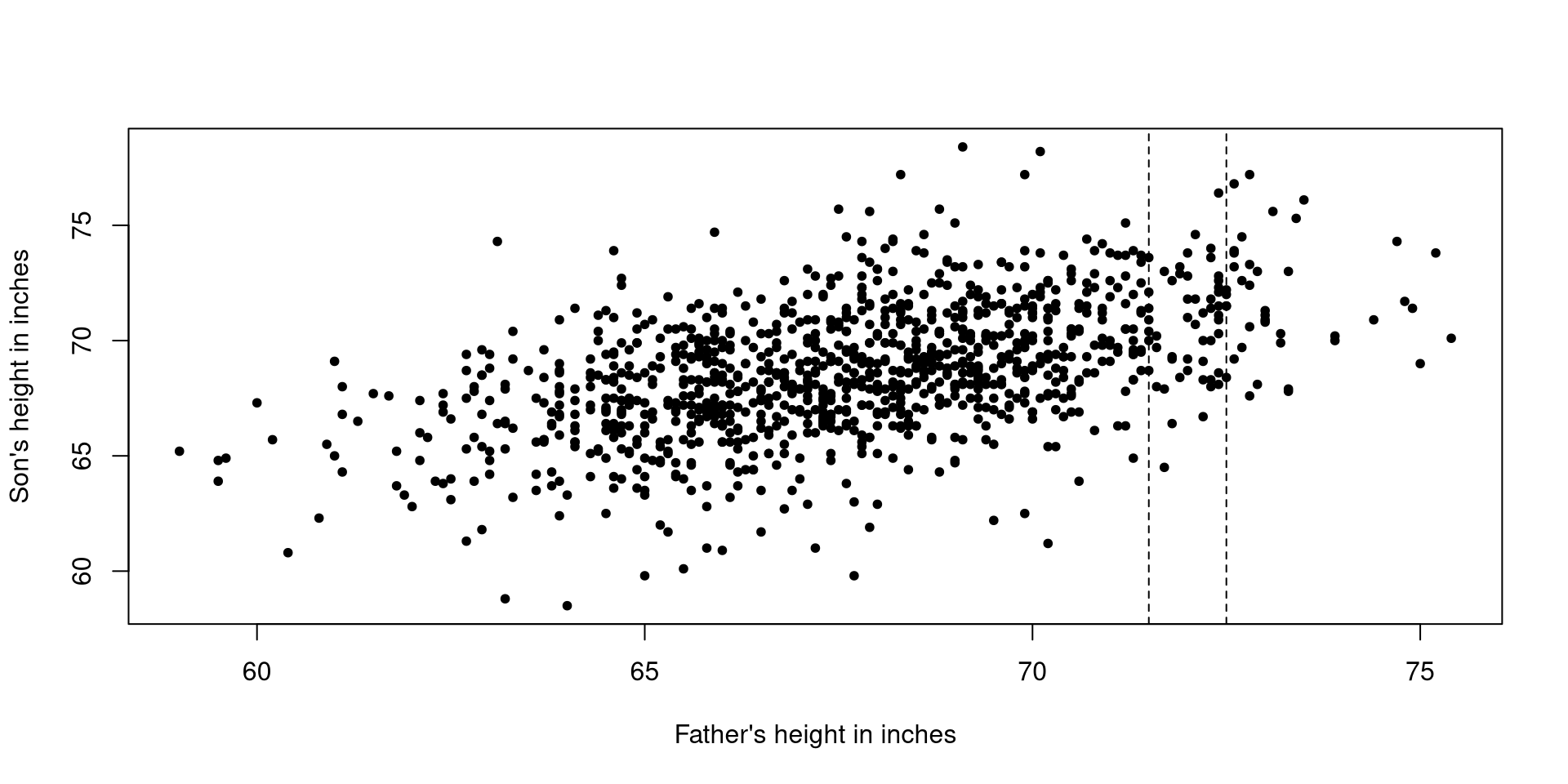
Let us look at that particular strip.
Let us look at another strip.
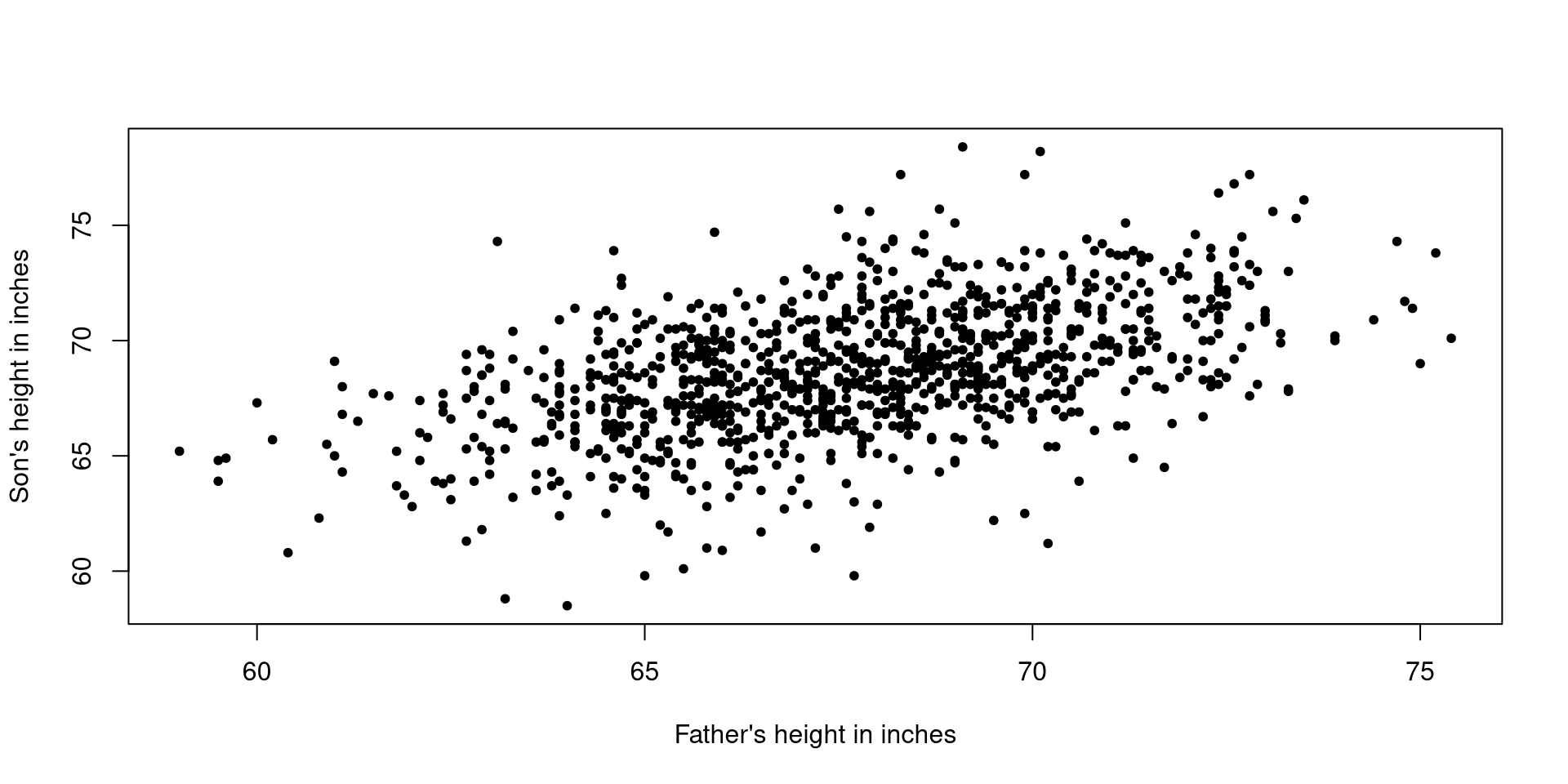
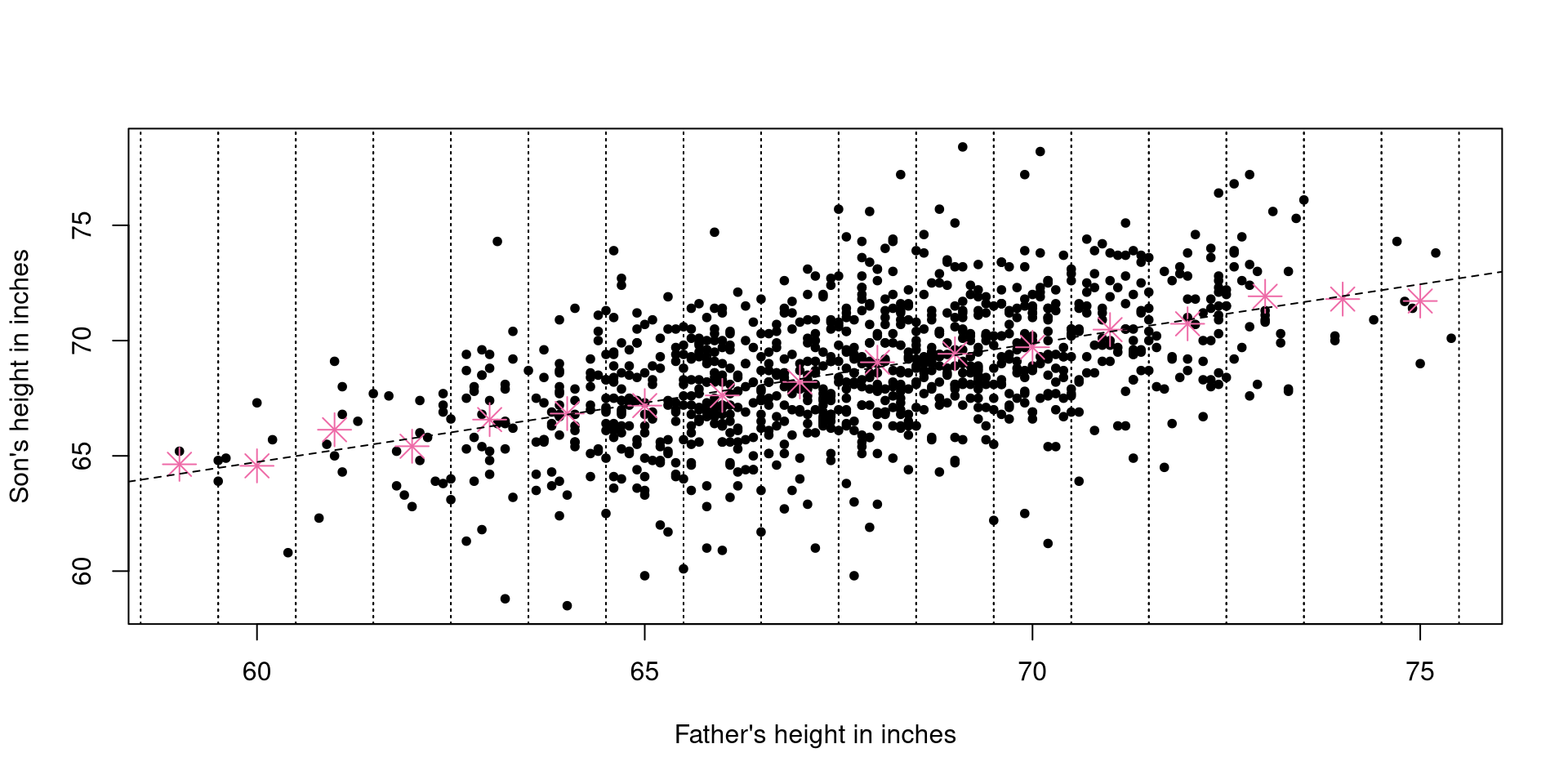
data <- read.csv("Pearson.csv")
par(pch = 20)
plot(data$Father, data$Son, xlab = "Father's height in inches", ylab = "Son's height in inches")
for(i in 59:75)
{
points(i , mean(subset(data, (data$Father >= (i-0.5) & data$Father <= (i+0.5)))$Son), pch = 8, col = "hotpink2", cex = 2)
abline(v = (i-0.5), lty = "dotted")
abline(v = (i+0.5), lty = "dotted")
}
abline(coef(lm(Son ~ Father, data = data)), lty = "dashed")mcas <- read.csv("mcas.csv")
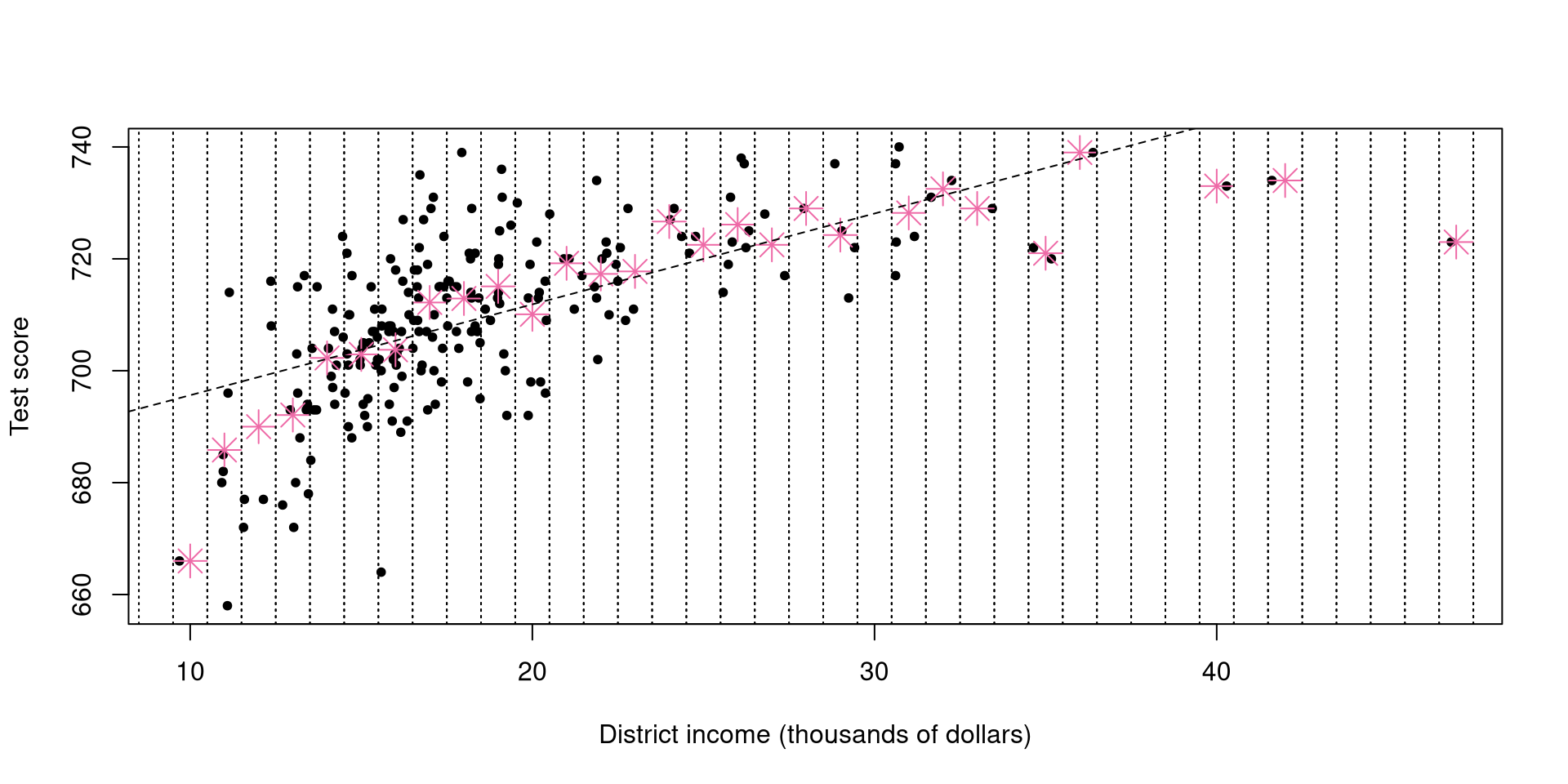
par(pch=20)
plot(mcas$percap, mcas$totsc4, xlab = "District income (thousands of dollars)", ylab = "Test score")
for(i in 9:50)
{
points(i , mean(subset(mcas, (mcas$percap >= (i-0.5) & mcas$percap <= (i+0.5)))$totsc4), pch = 8, col = "hotpink2", cex = 2)
abline(v = (i-0.5), lty = "dotted")
abline(v = (i+0.5), lty = "dotted")
}
abline(coef(lm(totsc4 ~ percap, data = mcas)), lty="dashed")mcas <- read.csv("mcas.csv")
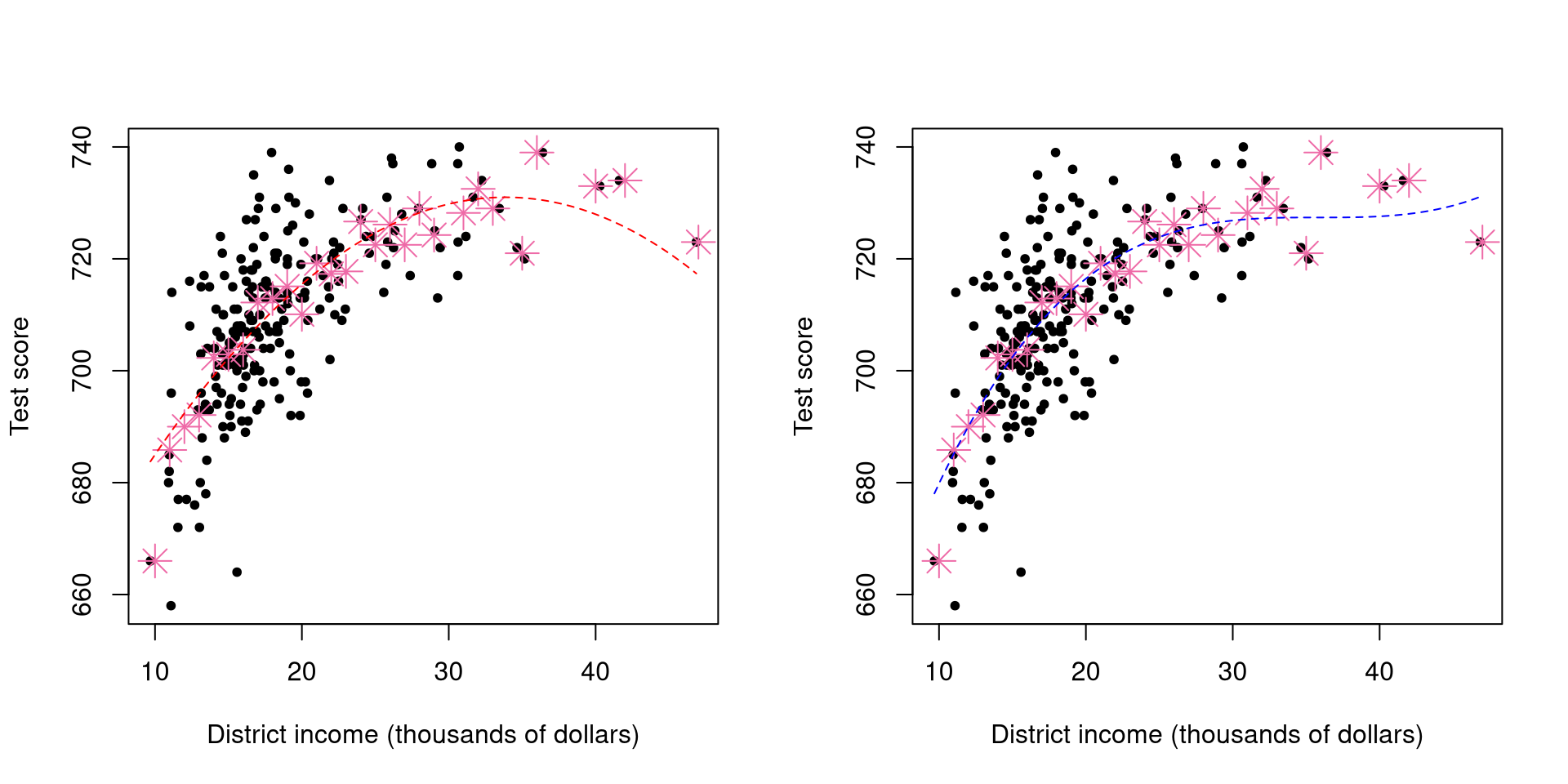
par(pch=20, mfrow = c(1, 2))
plot(mcas$percap, mcas$totsc4, xlab = "District income (thousands of dollars)", ylab = "Test score")
for(i in 9:50)
{
points(i , mean(subset(mcas, (mcas$percap >= (i-0.5) & mcas$percap <= (i+0.5)))$totsc4), pch = 8, col = "hotpink2", cex = 2)
}
curve(cbind(1, x, x^2) %*% coef(lm(totsc4 ~ percap + I(percap^2), data = mcas)), lty = "dashed", add = TRUE, col = "red")
plot(mcas$percap, mcas$totsc4, xlab = "District income (thousands of dollars)", ylab = "Test score")
for(i in 9:50)
{
points(i , mean(subset(mcas, (mcas$percap >= (i-0.5) & mcas$percap <= (i+0.5)))$totsc4), pch = 8, col = "hotpink2", cex = 2)
}
curve(cbind(1, x, x^2, x^3) %*% coef(lm(totsc4 ~ percap + I(percap^2) + I(percap^3), data = mcas)), lty = "dashed", add = TRUE, col = "blue")